I've mentioned before that APIs are a critical component of large enterprise software offerings. The largest vendors realize this and treat API design very seriously. Some vendors, of course, actually productize their APIs via SDKs with their own installers, release notes, etc. That's often the case when the product has a well-defined plug-in architecture, for example.
Many systems have multiple APIs these days, to accommodate various abstraction levels (programmatic vs. SOAP, for example), as well as to expose different kinds of functionality offered by different subsystems. There's also the (unfortunately) common situation where a vendor has chosen to expose programmatic functionality through a proprietary, non-standard scripting language. This becomes an API of its own as well.
If there were such a thing as a middleware API maturity model, "design-by-intention" would surely be one of the principal stages. APIs run the spectrum from those that have a fully project-managed development cycle of their own (complete with requirements-gathering, design docs and specifications, dev, QA testing, usability testing, documentation, etc.) to those that are put together on an ad-hoc basis by a few developers who happen to have the time to do it.
Quite a few APIs are what I would call accidental. They've been "built out on" organically over a period of years. They are what they are. They aren't intentionally designed; rather, their structure shadows that of the product's existing codebase, thus the API inherits from the product-development processes that preceded it, rather than having arisen through any well-defined design process of its own.
Ideally, it should be the other way around. If anything, the API should precede the software. At the very least, however, APIs need to be intentionally designed. There's too much riding on them to allow them to "just happen."
Of course, once an API is in place, it's hard to redesign it or refactor it. Legacy classes that follow legacy patterns have to be left in place for backward-compatibility reasons, lest any changes break customer code. New classes and methods get added, but few are removed.
An API that's been added onto incrementally over a period of many years may have accumulated a staggering design debt. After a point, reducing the debt becomes prohibitively painful. When that point has passed, it doesn't make sense to try to refactor the API unless the product itself is rewritten.
Alas, in the software world, there's no Magic Bailout to help with design debt.
My advice? If you're one of those software vendors who've built out on existing APIs in ad hoc fashion over a period of many years, now might be a good time to assess the state of your APIs. If nothing else, ask customers and partners (maybe even your own engineers) whether your APIs are doing the job as well as they could be. Consider doing usability studies. Do your APIs promote the use of accepted design patterns? Are classes and methods as self-explanatory as they could be? Do experienced developers need to go to classroom training for a week in order to become productive? Or can a competent developer become productive on his or her own, in a reasonably short period of time?
Take a stab at coming up with some metrics, and score your APIs as to usability (fitness to purpose). Put together a business case: How much extra ROI would your customers realize if your APIs were even, say, 10% or 20% more usable than they are now? How much ROI would your company realize?
Bottom line: Don't underestimate the importance of having good APIs. And don't assume that if the product design is good, APIs will take care of themselves. That's like saying if an airplane's design is good enough, it will fly itself. That's almost true. The problem is the word "almost."
Tuesday, March 31, 2009
Monday, March 30, 2009
Will there be a Java 7?
Stephen Colebourne penned an interesting blog not long ago about the possible fate of Java 7. He speculates that there will be a JDK 7 but not necessarily a Java 7. He points to the fact that there is no JSR for Java 7 (nothing comparable to JSR-270 for Java SE 6). Perhaps not coincidentally, every blog from a key Sun employee in recent times has referred to JDK 7, not Java 7.
There's also the fact that Sun has impeded progress of the Apache Harmony project by not responding to Apache's Open Letter to Sun Microsystems. Until that dispute is resolved, and until there's a JSR, Apache can't move forward with an open-source Java 7.
Sun, however, can move forward with a JDK 7. And that JDK can contain Sun-controlled pieces. There has been a lot of grumbling about this in blog posts around Project Jigsaw, the effort to modularize Java. (For an excellent post on this, with lively comments, see Neil's point-free blog. But also explore the Googlesphere on your own. This is a fast-moving story.)
People are coming to realize that Sun still has an iron grip on Java, and that the JCP process has not helped ensure the openness of Java, going forward. (Had Sun gone with another standards body for Java, things probably would be turning out differently right now.)
What amazes me, frankly, is that so many people thought Sun would ever relinquish control of Java in any meaningful sense. How could anyone be that naive?
The community's best hope of seeing Java unshackled from Sun is to see Sun be acquired by IBM (which, IMHO, is not a sure thing either). If IBM acquires Sun, I believe there is a 70% chance that IBM will make Java truly open and unencumbered. IBM will make it community property.
Right now, as things stand, there's too much entropy around Java 7 for it to ever see the light of day. I agree with Colebourne that we will almost certainly see a JDK 7. Beyond that, all bets are off. Don't count on seeing a Java 7 SE or Java 7 EE any time soon.
There's also the fact that Sun has impeded progress of the Apache Harmony project by not responding to Apache's Open Letter to Sun Microsystems. Until that dispute is resolved, and until there's a JSR, Apache can't move forward with an open-source Java 7.
Sun, however, can move forward with a JDK 7. And that JDK can contain Sun-controlled pieces. There has been a lot of grumbling about this in blog posts around Project Jigsaw, the effort to modularize Java. (For an excellent post on this, with lively comments, see Neil's point-free blog. But also explore the Googlesphere on your own. This is a fast-moving story.)
People are coming to realize that Sun still has an iron grip on Java, and that the JCP process has not helped ensure the openness of Java, going forward. (Had Sun gone with another standards body for Java, things probably would be turning out differently right now.)
What amazes me, frankly, is that so many people thought Sun would ever relinquish control of Java in any meaningful sense. How could anyone be that naive?
The community's best hope of seeing Java unshackled from Sun is to see Sun be acquired by IBM (which, IMHO, is not a sure thing either). If IBM acquires Sun, I believe there is a 70% chance that IBM will make Java truly open and unencumbered. IBM will make it community property.
Right now, as things stand, there's too much entropy around Java 7 for it to ever see the light of day. I agree with Colebourne that we will almost certainly see a JDK 7. Beyond that, all bets are off. Don't count on seeing a Java 7 SE or Java 7 EE any time soon.
Sunday, March 29, 2009
Where did all the documentation go?
From time to time, I find myself lamenting the sad state of technical documentation today. What's sad about it? Mostly the fact that it is going away.
I try not to be sad, because most things that go away, go away for good reasons. Documentation is going away for many reasons. But I fear few of them are good.
I think there are two main reasons for the steady disappearance of product documentation. One is that documentation is just plain expensive to produce. In my last documentation job, we had a combined doc team (across 3 geos) of around 20 people to produce user guides, admin guides, help files, release notes, developer doc, etc., for a J2EE-based suite of products that comprised somewhere around two million lines of Java code. It took a little over a year for our extended group (R&D, QA, Doc, project management, others) to crank out a major upgrade, so if you figure $80K per doc-team member (way too low if you consider HR and other burden), that's well over $1.5 million to create updated doc for a major release of a J2EE product. And that's before factoring in the enormous cost of localization.
Documentation is a huge cost factor in software development, and companies are looking for ways to trim costs. If you cut back on product doc and customers don't complain, there's a temptation to keep cutting. Eventually you end up with software engineers writing bits of doc because all the tech writers were laid off, but there'll be one guy who didn't get laid off who has to work like heck to wire it all up and make it continue to look like professionally written doc.
The other reason doc is going away is, who has time to read it? People expect to be able to use a product immediately. Which is fine if the product is so well designed, so "self documenting," that it needs no doc. But when is that ever the case?
What do people do, though, now that so many products come with so little useful documentation? The first thing people try is the Web, of course. If there's a wiki with good info, that's what people will gravitate to. But wikis have two problems, typically: spotty coverage, and flat organization (making it hard to find things).
If there's no wiki, customers will go to the user forums. This can be an excellent source of info, but again, the problem is one of organization and findability. The best information in the world is no good if you can't get to it.
When busy people can't figure out how something works on their own, what then? Well, in the case of complex enterprise systems, "what then" is classroom training, quite often. You send your key people to classroom training, and they come back and transfer knowledge to others in your organization. From that point on, it's the help desk that bears the brunt of the burden.
It's a sad state of affairs in some ways, but as I say, I try not to be sad about it, because there's no turning back the hands of time. There's no going back to the days of comprehensive, professionally written, properly indexed, nicely formatted, easy-on-the-eyes technical documentation. And after all, the software companies do have a legitimate point (speaking in a business sense only): If you can get away with not giving customers lavish documentation, why should you spend the money to produce it?
Of course, some companies do still invest heavily in producing good documentation. Some of the biggest names in the business are in that camp. But those are the exceptions.
I can think of one scenario in which it would make sense for documentation to go away, and that's if software suddenly became so self-documenting that there's no real need for documentation. Very little enterprise software falls in that category.
Ironically, the main beneficiary of all this is probably Google, the everything-gateway for doc. With the decline in packaged documentation comes (inevitably) more clicks for Google. Google itself, of course, is self-documenting.
Maybe that's where it all ends. Maybe Google is where doc goes to die.
I try not to be sad, because most things that go away, go away for good reasons. Documentation is going away for many reasons. But I fear few of them are good.
I think there are two main reasons for the steady disappearance of product documentation. One is that documentation is just plain expensive to produce. In my last documentation job, we had a combined doc team (across 3 geos) of around 20 people to produce user guides, admin guides, help files, release notes, developer doc, etc., for a J2EE-based suite of products that comprised somewhere around two million lines of Java code. It took a little over a year for our extended group (R&D, QA, Doc, project management, others) to crank out a major upgrade, so if you figure $80K per doc-team member (way too low if you consider HR and other burden), that's well over $1.5 million to create updated doc for a major release of a J2EE product. And that's before factoring in the enormous cost of localization.
Documentation is a huge cost factor in software development, and companies are looking for ways to trim costs. If you cut back on product doc and customers don't complain, there's a temptation to keep cutting. Eventually you end up with software engineers writing bits of doc because all the tech writers were laid off, but there'll be one guy who didn't get laid off who has to work like heck to wire it all up and make it continue to look like professionally written doc.
The other reason doc is going away is, who has time to read it? People expect to be able to use a product immediately. Which is fine if the product is so well designed, so "self documenting," that it needs no doc. But when is that ever the case?
What do people do, though, now that so many products come with so little useful documentation? The first thing people try is the Web, of course. If there's a wiki with good info, that's what people will gravitate to. But wikis have two problems, typically: spotty coverage, and flat organization (making it hard to find things).
If there's no wiki, customers will go to the user forums. This can be an excellent source of info, but again, the problem is one of organization and findability. The best information in the world is no good if you can't get to it.
When busy people can't figure out how something works on their own, what then? Well, in the case of complex enterprise systems, "what then" is classroom training, quite often. You send your key people to classroom training, and they come back and transfer knowledge to others in your organization. From that point on, it's the help desk that bears the brunt of the burden.
It's a sad state of affairs in some ways, but as I say, I try not to be sad about it, because there's no turning back the hands of time. There's no going back to the days of comprehensive, professionally written, properly indexed, nicely formatted, easy-on-the-eyes technical documentation. And after all, the software companies do have a legitimate point (speaking in a business sense only): If you can get away with not giving customers lavish documentation, why should you spend the money to produce it?
Of course, some companies do still invest heavily in producing good documentation. Some of the biggest names in the business are in that camp. But those are the exceptions.
I can think of one scenario in which it would make sense for documentation to go away, and that's if software suddenly became so self-documenting that there's no real need for documentation. Very little enterprise software falls in that category.
Ironically, the main beneficiary of all this is probably Google, the everything-gateway for doc. With the decline in packaged documentation comes (inevitably) more clicks for Google. Google itself, of course, is self-documenting.
Maybe that's where it all ends. Maybe Google is where doc goes to die.
Saturday, March 28, 2009

UI design the Atlas way
I recently watched the video explaining the Atlas visual app designer, and all I can say is, I'm favorably impressed. (Pass me another glass of that Kool-Aid, do you mind?)
In a nutshell, Atlas is a visual IDE for Object-J (an interesting subject unto itself), but before you run away screaming, understand that there is no need to learn a new language or deal with raw code unless you want to. Web designers who speak little or no JavaScript (and zero Java) can take this tool a long way. If you do nothing more with Atlas than use it to prototype user interfaces, you'll be way ahead of the game. It looks like a fine RUID tool (Rapid UI Design).
One of the striking things about Atlas is its own user interface. Watch the video. You'll notice that the user gestures for creating layouts and linking controls (buttons, etc.) to actions are simple and intuitive. (Pay special attention to the slider demo.) Some of the gestures and methodologies are used in other products, of course, but they've been integrated very effectively in Atlas. The overall effect is powerful.
This is the kind of UI that people in the Web Content Management System business (and others who need to give users a simple way to lay out web pages, forms, and dialogs) need to study carefully, in my opinion.
The only bad thing about Atlas: It isn't available for download yet; it will supposedly be released this summer (you can sign up for news announcements here). It will be interesting to see what people create with it.
In a nutshell, Atlas is a visual IDE for Object-J (an interesting subject unto itself), but before you run away screaming, understand that there is no need to learn a new language or deal with raw code unless you want to. Web designers who speak little or no JavaScript (and zero Java) can take this tool a long way. If you do nothing more with Atlas than use it to prototype user interfaces, you'll be way ahead of the game. It looks like a fine RUID tool (Rapid UI Design).
One of the striking things about Atlas is its own user interface. Watch the video. You'll notice that the user gestures for creating layouts and linking controls (buttons, etc.) to actions are simple and intuitive. (Pay special attention to the slider demo.) Some of the gestures and methodologies are used in other products, of course, but they've been integrated very effectively in Atlas. The overall effect is powerful.
This is the kind of UI that people in the Web Content Management System business (and others who need to give users a simple way to lay out web pages, forms, and dialogs) need to study carefully, in my opinion.
The only bad thing about Atlas: It isn't available for download yet; it will supposedly be released this summer (you can sign up for news announcements here). It will be interesting to see what people create with it.
Friday, March 27, 2009
What APIs can tell you about a product
I do a lot of in-depth product evaluations in my day job, mostly involving Content Management Systems (ranging from open-source systems to boutique $10K solutions to $100K-and-up suites), but sometimes also involving enterprise-search products, and a number of Digital Asset management offerings.
Many of these products are what I call "one size fits none" products. Some of them come with a lot of functionality out of the box, but almost no licensee will simply reskin the login page and use the product in production, unmodified: Complex organizations have complex needs that can only be met by building custom applications, or extending the product's existing applications. So at the level of something like Oracle UCM or Documentum, APIs become very important. A good API becomes a value multiplier, leading directly to better ROI. A bad API becomes a productivity sink and a vendor lock-in mechanism, leading to missed rollout dates, ongoing pain of ownership, and Rogaine addiction.
For this and other reasons (such as sheer morbid curiosity), I always try to get a look at a vendor's APIs before (or in the process of) evaluating a product. And I recommend you do, too. If you are involved in a product-selection effort, get input from your developers -- have them evaluate APIs as part of the product-evaluation process. Don't wait until after the deal is inked to find out whether the product's APIs are so problematic that your rollout schedule might have to undergo serious changes.
Since almost any serious system rollout involves a significant amount of custom development, your best chance at rolling out ahead of time and under budget is to go with a product that either already implements most of the features you need (not likely) or has powerful, easy-to-learn APIs that span a wide range of abstraction levels. At the lowest level, you want direct programmatic access to system services, and the ability to create or extend core objects. At a higher level, you want access to business objects, data sources, and component libraries, either through a low-level language, or a scripting language, preferably with a combination of server-side and client-side APIs (e.g., AJAX-enabled). At the highest level, you want to be able to get to services via REST calls.
What about SOAP? It depends. If you have sophisticated requirements around security, fault-handling policies, mediation between "nodes," complex payload bundles, etc., or you need to use JMS (say) instead of HTTP, a SOAP-based Web Services API can be important. It's not a terribly performant way to go, but if your SOAP services are used in overnight batch processing or long-running BPM processes, the performance penalty probably won't matter. What you want to avoid is using SOAP to fetch stock quotes (or similar sorts of things). That's where SOAP's overhead is not worth it.
Because of the potential for rapid application development, it's important (IMHO) that any product you're evaluating has some level of scripting support. (In other words, you don't want to be forced to use C# or Java for every little thing.) Here, the product support standard languages as opposed to proprietary, one-off languages. In this day and age, there is no excuse for making customers learn a proprietary language. "Proprietariness" should not surface as language-level syntax. Once you start investing in writing code in a proprietary language, you're entering the wonderful land of Vendor Lock-In. Beware.
I find that if a product is standards-driven and has well-designed APIs, developers don't need to take classroom training in order to be productive. They can go to work immediately (or at least, same-day). This is a good litmus test, I think. If your best coders have to take 3 days of classroom training in order to get beyond "Hello World," look long and hard at the product architecture and APIs.
Another danger sign: proprietary development tooling. If it's impossible to develop a custom component without a special purpose-designed vendor-supplied IDE, think about why that is. (Eclipse or Visual Studio plug-ins are fine; that's not a problem. What's potentially problematic is when a vendor has created a one-off IDE that you have to use in order to do custom development.) A standards-driven product seldom forces you to use special tools. That's one of the benefits of standards.
Ideally, a product's highest-level APIs should be able to support many, if not most, of your most common ("80% use case") needs. For example, basic CRUD operations (create, read, update, delete) should be possible using APIs that live at a higher level than raw Java. Granted, this won't always be possible; there are many scenarios in which safe, transactional access to data requires custom-written compiled code. But my point is, you shouldn't have to drop down into Java to get a stock quote. Simple things should be easy.
Look for API features that favor declarative versus imperative-style programming. Configuration settings, hard-coded values, and things that don't change very often should be in an XML (or other text-based) file. You shouldn't have to code raw Java to change the color of a UI component.
There's a lot more to say on the subject of APIs; I've only touched on some very-high-level points here. But these are the kind of basics you need to pay attention to when evaluating a complex product like a CMS or DAM system, because it's easy to be (falsely) comforted by a vendor's claim of "extensive Web Services support" or "AJAX support," or "comprehensive Java APIs." Every middleware solution has APIs. The question is, how many hours, days, or weeks does it take to become productive with them -- and can they really do all the things you need them to do?
Many of these products are what I call "one size fits none" products. Some of them come with a lot of functionality out of the box, but almost no licensee will simply reskin the login page and use the product in production, unmodified: Complex organizations have complex needs that can only be met by building custom applications, or extending the product's existing applications. So at the level of something like Oracle UCM or Documentum, APIs become very important. A good API becomes a value multiplier, leading directly to better ROI. A bad API becomes a productivity sink and a vendor lock-in mechanism, leading to missed rollout dates, ongoing pain of ownership, and Rogaine addiction.
For this and other reasons (such as sheer morbid curiosity), I always try to get a look at a vendor's APIs before (or in the process of) evaluating a product. And I recommend you do, too. If you are involved in a product-selection effort, get input from your developers -- have them evaluate APIs as part of the product-evaluation process. Don't wait until after the deal is inked to find out whether the product's APIs are so problematic that your rollout schedule might have to undergo serious changes.
Since almost any serious system rollout involves a significant amount of custom development, your best chance at rolling out ahead of time and under budget is to go with a product that either already implements most of the features you need (not likely) or has powerful, easy-to-learn APIs that span a wide range of abstraction levels. At the lowest level, you want direct programmatic access to system services, and the ability to create or extend core objects. At a higher level, you want access to business objects, data sources, and component libraries, either through a low-level language, or a scripting language, preferably with a combination of server-side and client-side APIs (e.g., AJAX-enabled). At the highest level, you want to be able to get to services via REST calls.
What about SOAP? It depends. If you have sophisticated requirements around security, fault-handling policies, mediation between "nodes," complex payload bundles, etc., or you need to use JMS (say) instead of HTTP, a SOAP-based Web Services API can be important. It's not a terribly performant way to go, but if your SOAP services are used in overnight batch processing or long-running BPM processes, the performance penalty probably won't matter. What you want to avoid is using SOAP to fetch stock quotes (or similar sorts of things). That's where SOAP's overhead is not worth it.
Because of the potential for rapid application development, it's important (IMHO) that any product you're evaluating has some level of scripting support. (In other words, you don't want to be forced to use C# or Java for every little thing.) Here, the product support standard languages as opposed to proprietary, one-off languages. In this day and age, there is no excuse for making customers learn a proprietary language. "Proprietariness" should not surface as language-level syntax. Once you start investing in writing code in a proprietary language, you're entering the wonderful land of Vendor Lock-In. Beware.
I find that if a product is standards-driven and has well-designed APIs, developers don't need to take classroom training in order to be productive. They can go to work immediately (or at least, same-day). This is a good litmus test, I think. If your best coders have to take 3 days of classroom training in order to get beyond "Hello World," look long and hard at the product architecture and APIs.
Another danger sign: proprietary development tooling. If it's impossible to develop a custom component without a special purpose-designed vendor-supplied IDE, think about why that is. (Eclipse or Visual Studio plug-ins are fine; that's not a problem. What's potentially problematic is when a vendor has created a one-off IDE that you have to use in order to do custom development.) A standards-driven product seldom forces you to use special tools. That's one of the benefits of standards.
Ideally, a product's highest-level APIs should be able to support many, if not most, of your most common ("80% use case") needs. For example, basic CRUD operations (create, read, update, delete) should be possible using APIs that live at a higher level than raw Java. Granted, this won't always be possible; there are many scenarios in which safe, transactional access to data requires custom-written compiled code. But my point is, you shouldn't have to drop down into Java to get a stock quote. Simple things should be easy.
Look for API features that favor declarative versus imperative-style programming. Configuration settings, hard-coded values, and things that don't change very often should be in an XML (or other text-based) file. You shouldn't have to code raw Java to change the color of a UI component.
There's a lot more to say on the subject of APIs; I've only touched on some very-high-level points here. But these are the kind of basics you need to pay attention to when evaluating a complex product like a CMS or DAM system, because it's easy to be (falsely) comforted by a vendor's claim of "extensive Web Services support" or "AJAX support," or "comprehensive Java APIs." Every middleware solution has APIs. The question is, how many hours, days, or weeks does it take to become productive with them -- and can they really do all the things you need them to do?
Thursday, March 26, 2009
Twice-as-fast isn't good enough
I've been involved in a number of performance tuning efforts over the years, and one thing I've noticed over and over again is how hard it is to get anyone to notice a 2x speed increase.
I mentioned this to an acquaintance once, a programmer of great skill whose opinion I value. He nodded and said matter-of-factly: "A twofold speedup is not a worthwhile performance gain."
I was struck by the finality of his statement. In fact, I questioned it. He challenged me back:
"What's something you do every day on the computer that takes a significant amount of time?" he quizzed me.
"Well, rotating a large image in Photoshop takes a long time," I said. (Bear in mind, this was in the early 1990s, when most Macs ran at 10 MHz.)
"How long does that take?" John asked.
"It can easily take 45 seconds," I said.
"Okay, so if it took 22 seconds, would it change your life?"
I stopped and thought. I could see where he was going. He was right, of course. Reducing a 45-second job to 20 seconds, or even ten (a speedup of more than four-fold), would not materially affect my productivity or my quality of life; I would still be spending way too much time babysitting the machine, waiting for it to finish a fairly simple operation.
My friend made the case that when people have to spend more than five seconds waiting for the machine to finish doing something, it becomes an issue. He cited some research (by HP? I can't remember) to the effect that if more than five seconds elapses with no visual indication of anything changing, most people start to worry that the machine might be locking up. Mind you, this was back when desktop computers were single-tasking and most applications lacked a "progress bar" for lengthy operations. (Photoshop was an exception.) You couldn't switch contexts and go do something else in another open program. You had to wait patiently and hope the operation finished normally. On the Mac, you had the spinning "beachball cursor," which you hoped would eventually stop spinning. Sometimes it didn't.
I asked my friend what kind of performance improvement he considered "worthwhile." He said: "An order of magnitude."
I thought about it. He was right. The lengthy operations that drove me crazy on a regular basis tended to be under a minute in length (anything longer than that meant taking a coffee break), and obviously, shortening a 60-second operation to 6 seconds would be a quality-of-life boon (it would positively impact productivity), whereas shortening it to 30 seconds would make little difference.
In the late 1990s, I bought an aftermarket CPU upgrade for one of my Macs. It boosted overall processing speed by a factor of two-and-a-half. I hardly noticed. My PageMaker file saves went from two minutes to one. My Photoshop image-rotates that previously took 30 seconds, took about 15. The misery factor went down 50%. But I was still miserable.
So nowadays, when I hear someone (like Sun, with its ZFS file system) bragging about a 100% speedup of this-or-that operation because of realtime compression (or whatever), I just snicker. In this business, a two-fold speedup (of nearly anything) buys you 18 months in Moore time; then you're back where you started.
Don't delude yourself. In very few cases will your life be changed by a two-fold speedup of anything computer-related. If your business plan (for a new technology) is predicated on speed, and the promised performance boost is less than a factor of ten (a full order of magnitude), rethink what you're doing. "Twice as fast" is not a competitive advantage. Not by a long shot.
I mentioned this to an acquaintance once, a programmer of great skill whose opinion I value. He nodded and said matter-of-factly: "A twofold speedup is not a worthwhile performance gain."
I was struck by the finality of his statement. In fact, I questioned it. He challenged me back:
"What's something you do every day on the computer that takes a significant amount of time?" he quizzed me.
"Well, rotating a large image in Photoshop takes a long time," I said. (Bear in mind, this was in the early 1990s, when most Macs ran at 10 MHz.)
"How long does that take?" John asked.
"It can easily take 45 seconds," I said.
"Okay, so if it took 22 seconds, would it change your life?"
I stopped and thought. I could see where he was going. He was right, of course. Reducing a 45-second job to 20 seconds, or even ten (a speedup of more than four-fold), would not materially affect my productivity or my quality of life; I would still be spending way too much time babysitting the machine, waiting for it to finish a fairly simple operation.
My friend made the case that when people have to spend more than five seconds waiting for the machine to finish doing something, it becomes an issue. He cited some research (by HP? I can't remember) to the effect that if more than five seconds elapses with no visual indication of anything changing, most people start to worry that the machine might be locking up. Mind you, this was back when desktop computers were single-tasking and most applications lacked a "progress bar" for lengthy operations. (Photoshop was an exception.) You couldn't switch contexts and go do something else in another open program. You had to wait patiently and hope the operation finished normally. On the Mac, you had the spinning "beachball cursor," which you hoped would eventually stop spinning. Sometimes it didn't.
I asked my friend what kind of performance improvement he considered "worthwhile." He said: "An order of magnitude."
I thought about it. He was right. The lengthy operations that drove me crazy on a regular basis tended to be under a minute in length (anything longer than that meant taking a coffee break), and obviously, shortening a 60-second operation to 6 seconds would be a quality-of-life boon (it would positively impact productivity), whereas shortening it to 30 seconds would make little difference.
In the late 1990s, I bought an aftermarket CPU upgrade for one of my Macs. It boosted overall processing speed by a factor of two-and-a-half. I hardly noticed. My PageMaker file saves went from two minutes to one. My Photoshop image-rotates that previously took 30 seconds, took about 15. The misery factor went down 50%. But I was still miserable.
So nowadays, when I hear someone (like Sun, with its ZFS file system) bragging about a 100% speedup of this-or-that operation because of realtime compression (or whatever), I just snicker. In this business, a two-fold speedup (of nearly anything) buys you 18 months in Moore time; then you're back where you started.
Don't delude yourself. In very few cases will your life be changed by a two-fold speedup of anything computer-related. If your business plan (for a new technology) is predicated on speed, and the promised performance boost is less than a factor of ten (a full order of magnitude), rethink what you're doing. "Twice as fast" is not a competitive advantage. Not by a long shot.
Wednesday, March 25, 2009
Seat-based software licensing has to stop
I just wrote a blog on this subject for CMS Watch, available here. The basic premise (just to boil it down) is that monitoring, auditing, enforcing, administering, and just plain dealing with seat-based licensing of enterprise software is a huge, huge problem, in a world that doesn't need more problems.
More to the point, it's out of step with reality. It's certainly not how large IT organizations want to do business these days. Everyone I know hates seat-based pricing. It's antiquated.
In my CMS Watch post, I didn't specify what I would propose as an alternative to per-seat pricing. That's because my proposed alternative might strike some people as a bit radical.
IMHO, the way to price enterprise software going forward is to charge a monthly subscription fee for support. That's right: give away the software for free. Charge only for support. And maybe charge something here and there for high-value specialty add-ons (your connector-du-jour), but mainly for support. To account for scalability, maybe set fees on a per-server or per-installed-instance basis (but certainly not on a per-CPU or per-core basis). Install an instance of XYZ CMS on one box, pay one monthly fee. That's how it should be.
The era of million-dollar lump-sum front-weighted CapEx-accounting enterprise software deals is over. It's gone, just like the newspaper business. Dead, finished, done. I have blogged on this before.
Oh sure, there are still million-dollar deals being cut as we speak. It's like the tail of a dead brontosaurus still flailing around, days after the brain has died.
Can big software vendors survive by giving software away for free and charging only for support and services? Actually, yes, I think so. It will be a painful transition for many big-name software giants. But in the end, I think it will work. A number of commercial open-source vendors have proven, in fact, that it will work.
But also, the cable company has proven that it will work.
As I told a colleague at CMS Watch, the cable company (very wisely) does not charge you $10,000 for a cable box. Instead, they give you the cable box (and even install it for free, on site). Then they charge you a nominal monthly fee (if $100 a month, plus or minus $60, can be called nominal) for content. After 8 years, you've paid the cable company $10,000. But you've paid them in a manner that's acceptable to you. And in the meantime, you're free to switch to something else, or cancel.
Big software vendors who "get" this will survive. Those that don't, won't. This is a time of structural change for many businesses (such as, for example, the newspaper business), and the world of enterprise software is not immune. Serious changes are ahead. The survivors will stay out in front of these changes, starting yesterday. The non-survivors... well, they're still flailing their tails.
More to the point, it's out of step with reality. It's certainly not how large IT organizations want to do business these days. Everyone I know hates seat-based pricing. It's antiquated.
In my CMS Watch post, I didn't specify what I would propose as an alternative to per-seat pricing. That's because my proposed alternative might strike some people as a bit radical.
IMHO, the way to price enterprise software going forward is to charge a monthly subscription fee for support. That's right: give away the software for free. Charge only for support. And maybe charge something here and there for high-value specialty add-ons (your connector-du-jour), but mainly for support. To account for scalability, maybe set fees on a per-server or per-installed-instance basis (but certainly not on a per-CPU or per-core basis). Install an instance of XYZ CMS on one box, pay one monthly fee. That's how it should be.
The era of million-dollar lump-sum front-weighted CapEx-accounting enterprise software deals is over. It's gone, just like the newspaper business. Dead, finished, done. I have blogged on this before.
Oh sure, there are still million-dollar deals being cut as we speak. It's like the tail of a dead brontosaurus still flailing around, days after the brain has died.
Can big software vendors survive by giving software away for free and charging only for support and services? Actually, yes, I think so. It will be a painful transition for many big-name software giants. But in the end, I think it will work. A number of commercial open-source vendors have proven, in fact, that it will work.
But also, the cable company has proven that it will work.
As I told a colleague at CMS Watch, the cable company (very wisely) does not charge you $10,000 for a cable box. Instead, they give you the cable box (and even install it for free, on site). Then they charge you a nominal monthly fee (if $100 a month, plus or minus $60, can be called nominal) for content. After 8 years, you've paid the cable company $10,000. But you've paid them in a manner that's acceptable to you. And in the meantime, you're free to switch to something else, or cancel.
Big software vendors who "get" this will survive. Those that don't, won't. This is a time of structural change for many businesses (such as, for example, the newspaper business), and the world of enterprise software is not immune. Serious changes are ahead. The survivors will stay out in front of these changes, starting yesterday. The non-survivors... well, they're still flailing their tails.
Console AJAX: Intersecting two sets of Twitter users
I promised yesterday that we'd do a bit of console scripting today, illustrating three semi-useful techniques:
1. Doing AJAX in the console.
2. Using the Twitter REST API as part of No. 1. In particular, we'll try one of the new "social graph" calls.
3. We'll intersect two sets, in JavaScript. And do it in linear time.
Twitter's social-graph methods are very straightforward. (The relevant API doc is here and I won't repeat it.) They're intended to let you retrieve all of a person's followers, or all of the person's "friends" (followees), all at once, using one HTTP GET. You can get the results back either as JSON or as XML. Your choice.
The results come back as an array of user IDs. Nothing else: no name or profile info or anything like that. You can certainly convert an ID into extended user info for that person using other methods. But you'll have to do it one user (one ID) at a time, which can be slow (and also, it quickly eats into the Twitter-imposed bandwidth limit of 100 queries per 60-minute time period).
What's the point of dealing with numeric IDs in the first place? Well, the idea is that if you are mainly doing social-analysis types of things (e.g., identifying and characterizing FOAF clusters, trying to figure out how and why and when people form social bonds), you don't really need anybody's profile information for that. You can do an awful lot just by fetching and comparing sets of ID numbers.
For example, suppose you want to know how many of vignettecorp's followers are also following opentext. (These are the corporate Twitter account names for Vignette Corporation and Open Text, respectively.) As of right now, as I sit here typing this, vignettecorp has 421 followers and opentext has 417. How much overlap is there? How many followers of one are also following the other?
To answer that question, we need to obtain the two groups of followers and intersect them. That's what the following code does. Using AJAX, we send two GETs to Twitter.com's server, so as to receive the "follower" arrays for vignettecorp and opentext. We convert each array to a set. Then we intersect the sets. Finally, we paint the results to the current browser window.
We can do all of this from the Firebug console, if you're a Firefox+Firebug user. Just cut and paste the following code to the console and run it. NOTE: Before doing this, be sure to point your browser to Twitter.com (and log on, if need be). You need to have a Twitter page (any Twitter page) open before you begin, as otherwise you'll get a cross-site AJAX error.
When I ran this code last night, it said there were 63 user IDs in common between vignettecorp and opentext. That's substantial overlap. Marketers live for this kind of information.
Note that for speed, I convert the user-ID arrays to JavaScript objects (where the user ID becomes a property name) so that we can check for membership using JavaScript's in syntax. This lets us avoid a horrible speed hit. If we were to do a brute-force direct comparison of every member of setA against every member of setB, the intersection routine would execute in N-squared time, which may be okay for small sets, but is intolerable for large ones. In this case, with ~400 members in each set, an N-squared algorithm requires ~160K comparisons. But imagine if you were to intersect Scobleizer's follower list (~75K followers) with guykawasaki's (~93K). That comes to about 7 billion comparison operations. You don't want to try that with JavaScript.
Note, incidentally, that if you want to take the difference of two sets, you can just change the line of code in the intersection routine that says
So there you go. If you're a social-graph researcher, or maybe if you just want to build your own set of Twitter list-management tools, the above code should get you started. And now you also know how to do some AJAX in the (Firebug) console, without blowing a hand or a foot off.
Still, keep some first-aid supplies handy.
1. Doing AJAX in the console.
2. Using the Twitter REST API as part of No. 1. In particular, we'll try one of the new "social graph" calls.
3. We'll intersect two sets, in JavaScript. And do it in linear time.
Twitter's social-graph methods are very straightforward. (The relevant API doc is here and I won't repeat it.) They're intended to let you retrieve all of a person's followers, or all of the person's "friends" (followees), all at once, using one HTTP GET. You can get the results back either as JSON or as XML. Your choice.
The results come back as an array of user IDs. Nothing else: no name or profile info or anything like that. You can certainly convert an ID into extended user info for that person using other methods. But you'll have to do it one user (one ID) at a time, which can be slow (and also, it quickly eats into the Twitter-imposed bandwidth limit of 100 queries per 60-minute time period).
What's the point of dealing with numeric IDs in the first place? Well, the idea is that if you are mainly doing social-analysis types of things (e.g., identifying and characterizing FOAF clusters, trying to figure out how and why and when people form social bonds), you don't really need anybody's profile information for that. You can do an awful lot just by fetching and comparing sets of ID numbers.
For example, suppose you want to know how many of vignettecorp's followers are also following opentext. (These are the corporate Twitter account names for Vignette Corporation and Open Text, respectively.) As of right now, as I sit here typing this, vignettecorp has 421 followers and opentext has 417. How much overlap is there? How many followers of one are also following the other?
To answer that question, we need to obtain the two groups of followers and intersect them. That's what the following code does. Using AJAX, we send two GETs to Twitter.com's server, so as to receive the "follower" arrays for vignettecorp and opentext. We convert each array to a set. Then we intersect the sets. Finally, we paint the results to the current browser window.
We can do all of this from the Firebug console, if you're a Firefox+Firebug user. Just cut and paste the following code to the console and run it. NOTE: Before doing this, be sure to point your browser to Twitter.com (and log on, if need be). You need to have a Twitter page (any Twitter page) open before you begin, as otherwise you'll get a cross-site AJAX error.
I haven't done any error-checking and the code isn't going to win any awards for prettiness (or safety), but hey, this is console code. If it detonates, no one goes to the hospital.function intersect ( setA, setB ) {
var set = {};
for ( var i in setA )
if ( i in setB )
set[ i ] = i;
return set;
}
// AJAX magic
function getIDsForUser( user ) {
var req = new XMLHttpRequest( );
var url =
"http://twitter.com/followers/ids/" + user + ".json";req.open( 'GET', url, false );return eval( req.responseText );
req.send( null );
}
// Put each member of an array into
// a property of the same name in an
// object called 'set'
function arrayToSet( array ) {
var set = {};
var id;
for (;array.length;) {id = array.pop( );}
set[ id ] = id ;
return set;
}
// This is arbitrary. Rewrite to suit your
// display needs.
function output( data ) {
var a=0; var ar=[];
for ( var id in data )
ar.push( ++a + ". <id>" +
data[ id ] + "</id>" );
document.body.innerHTML =
"TOTAL: " + ar.length + " IDs in common.<br/>";
document.body.innerHTML += ar.join( "<br/>" );
}
// ============= main( ) =============
// Everything starts from here
( function main( ) {
var user1 = "vignettecorp";
var user2 = "opentext";
var user1array = getIDsForUser( user1 );
var user1set = arrayToSet( user1array );
var user2array = getIDsForUser( user2 );
var user2set = arrayToSet( user2array );
// intersect the two sets of users
var intersection = intersect( user1set,user2set );
output( intersection );
} ) ( );
When I ran this code last night, it said there were 63 user IDs in common between vignettecorp and opentext. That's substantial overlap. Marketers live for this kind of information.
Note that for speed, I convert the user-ID arrays to JavaScript objects (where the user ID becomes a property name) so that we can check for membership using JavaScript's in syntax. This lets us avoid a horrible speed hit. If we were to do a brute-force direct comparison of every member of setA against every member of setB, the intersection routine would execute in N-squared time, which may be okay for small sets, but is intolerable for large ones. In this case, with ~400 members in each set, an N-squared algorithm requires ~160K comparisons. But imagine if you were to intersect Scobleizer's follower list (~75K followers) with guykawasaki's (~93K). That comes to about 7 billion comparison operations. You don't want to try that with JavaScript.
Note, incidentally, that if you want to take the difference of two sets, you can just change the line of code in the intersection routine that says
if ( i in setB )to:
if ( !( i in setB ) )But also note, of course, that set-subtraction is not commutative.
So there you go. If you're a social-graph researcher, or maybe if you just want to build your own set of Twitter list-management tools, the above code should get you started. And now you also know how to do some AJAX in the (Firebug) console, without blowing a hand or a foot off.
Still, keep some first-aid supplies handy.
Tuesday, March 24, 2009
Do-less go-fast, revisited
Yesterday, someone I follow on Twitter (@johnstack) said he enjoyed my post on writing faster code and asked if I'd refer to some examples of "do less, go fast."
Canonical examples from Algorithms 101 abound. I won't attempt to list them. Quicksort versus bubble-sort is an example that comes to mind (although worst-case performance is actually the same for both of those algorithms -- as is often true of divide-and-conquer approaches).
One of the most outstanding do-less algorithms of all time would have to be the Fast Fourier Transform, anticipated in 1805 by Carl Friedrich Gauss but made popular by Cooley and Tukey in 1962.
"Do less" doesn't always mean choosing a different algorithm. Sometimes you just need to parameterize the problem properly. I don't mean "parameterize" in a rigorous mathematical sense. What I'm talking about is rethinking the problem so you can define it (and attack it) in some fundamentally new way. You can find plenty of examples of this sort of thing in graphics programming, particularly 3D graphics . The Graphics Gems series of books abounds with examples of "doing less to go fast." All the source code (mostly C) from these books can be downloaded here, by the way.
I wrote an article for MacTech in 1999 on fast graphics-rendering strategies for the Mac, back when Apple was using PowerPC processors. That article contains a lot of do-stuff-faster tips and tricks, some of which can certainly be adapted to non-Mac systems. (If you like the article, or even if you don't, you might also want to look into dope vectors, sometimes called Iliffe arrays.)
My son (who is 14 years old) showed me a particularly egregious example of code-in-need-of-optimization the other day. Justin is a big fan of Runescape (the massive online adventure game), and he obtained Java source code to one of many knock-offs of the Runescape server that are floating around on the web. I looked at the main loop and sat there stunned for a few minutes. It contained easily the largest continuous sequence of if-elses I've ever seen. The if-elses were piled on so thick that when Justin tried to insert one extra if-else expression of his own, the class would no longer compile! "Code is too big" (or something like that) was the error message. It turns out Java has a hard-coded max size limit, per method, of 64K (in source code). Sun was way too lenient here, though. I think the limit should be something closer to 8K.
This is the kind of thing that, if it were in C++ or JavaScript (or a language that supports pointers-to-functions), would be a prime candidate for jump-table conflation. The natural syntax for long runs of if-elses in C, Java, or JavaScript is, of course, the switch statement, which the compiler (under the covers) implements as a jump table, usually. But you can also implement it yourself, directly. In JavaScript:
The moral, in this case, is that whenever you see a big, long run of if-elses, consider that someone has handed you an optimization opportunity.
In tomorrow's post, I'm going to run through some code for doing fast set manipulation in JavaScript. Just for fun, I'll throw in some console AJAX, and we'll have a quick look at Twitter's social-graph REST API. The snippets I want to show you won't win any prizes for elegance, but hey, this is console code we're talking about. Prettiness isn't on the requirements list.
Later.
Canonical examples from Algorithms 101 abound. I won't attempt to list them. Quicksort versus bubble-sort is an example that comes to mind (although worst-case performance is actually the same for both of those algorithms -- as is often true of divide-and-conquer approaches).
One of the most outstanding do-less algorithms of all time would have to be the Fast Fourier Transform, anticipated in 1805 by Carl Friedrich Gauss but made popular by Cooley and Tukey in 1962.
"Do less" doesn't always mean choosing a different algorithm. Sometimes you just need to parameterize the problem properly. I don't mean "parameterize" in a rigorous mathematical sense. What I'm talking about is rethinking the problem so you can define it (and attack it) in some fundamentally new way. You can find plenty of examples of this sort of thing in graphics programming, particularly 3D graphics . The Graphics Gems series of books abounds with examples of "doing less to go fast." All the source code (mostly C) from these books can be downloaded here, by the way.
I wrote an article for MacTech in 1999 on fast graphics-rendering strategies for the Mac, back when Apple was using PowerPC processors. That article contains a lot of do-stuff-faster tips and tricks, some of which can certainly be adapted to non-Mac systems. (If you like the article, or even if you don't, you might also want to look into dope vectors, sometimes called Iliffe arrays.)
My son (who is 14 years old) showed me a particularly egregious example of code-in-need-of-optimization the other day. Justin is a big fan of Runescape (the massive online adventure game), and he obtained Java source code to one of many knock-offs of the Runescape server that are floating around on the web. I looked at the main loop and sat there stunned for a few minutes. It contained easily the largest continuous sequence of if-elses I've ever seen. The if-elses were piled on so thick that when Justin tried to insert one extra if-else expression of his own, the class would no longer compile! "Code is too big" (or something like that) was the error message. It turns out Java has a hard-coded max size limit, per method, of 64K (in source code). Sun was way too lenient here, though. I think the limit should be something closer to 8K.
This is the kind of thing that, if it were in C++ or JavaScript (or a language that supports pointers-to-functions), would be a prime candidate for jump-table conflation. The natural syntax for long runs of if-elses in C, Java, or JavaScript is, of course, the switch statement, which the compiler (under the covers) implements as a jump table, usually. But you can also implement it yourself, directly. In JavaScript:
// horrible Runescape hacker way:Ideally, of course, you'd initialize the (static) table once and keep a permanent copy somewhere so you don't always have to create it each time you enter the updateUser() method, but even if you create it every time, it's still cheaper than crunching through a ridiculously long list of if-elses.
function updateUser( user ) {
if ( user.something == State.GOOD )
handleGood( user );
else if ( user.something == State.BAD )
handleBad( user );
else if ( user.something == State.TERRIBLE )
handleTerrible( user );
else if ( user.something == State.MESSED_UP )
handleMessedUp( user );
else if [ ... ] // 64Kbytes more of this
}
// jump-table way (error checking omitted):
function updateUser( user ) {
var table = {
State.GOOD : handleGood,
State.BAD : handleBad,
State.TERRIBLE : handleTerrible,
State.MESSED_UP : handleMessedUp
};
table[ user.something ]( user ); // dispatch
}
The moral, in this case, is that whenever you see a big, long run of if-elses, consider that someone has handed you an optimization opportunity.
In tomorrow's post, I'm going to run through some code for doing fast set manipulation in JavaScript. Just for fun, I'll throw in some console AJAX, and we'll have a quick look at Twitter's social-graph REST API. The snippets I want to show you won't win any prizes for elegance, but hey, this is console code we're talking about. Prettiness isn't on the requirements list.
Later.
Monday, March 23, 2009
How to write fast code
There was a time, early in my programming career, when I needed to rewrite a particular program (a very small one) to make it run faster. I was quite new to programming and thought that the way to get something to run faster was to rewrite it in assembly. In those days, you could unroll a loop in assembly and pretty much count on getting a worthwhile speedup, if it was a tight loop to begin with.
Fortunately, I had a fabulous mentor in those days, a coder with wisdom and experience far beyond his years. The person in question was a first-class code ninja and a master circuit designer, a genius of Woz-like proportions. Silicon obeyed him the way marble obeyed Michelangelo.
When it came to code, John could do astounding things. He could optimize (and did optimize) virtually any algorithm for any situation, and do it in so little code that you'd sit there studying the printout, wondering where the heck the algorithm went! I remember John had this peculiar way of making loops vanish, for example. They'd turn into table-lookups or recursion or self-modifying code, or some combination of the three.
One day my mentor asked me what I was working on and I told him. I mentioned that I was frantically searching for a way to speed up my little program. I described a few of the things I'd tried so far. He listened intently.
When I was done talking, John gave me some of the most profound advice any programming expert has ever given me. (It was profound for me, at the time. Maybe it'll be stupid-sounding to you.)
"The CPU," he said, "runs at a certain speed. It can execute a fixed number of instructions per second, and no more. There is a finite limit to how many instructions per second it can execute. Right?"
"Right," I said.
"So there is no way, really, to make code go faster, because there is no way to make instructions execute faster. There is only such a thing as making the machine do less."
He paused for emphasis.
"To go fast," he said slowly, "do less."
To go fast, do less. Do less; go fast. Yes, of course. It makes perfect sense. There's no other way to make a program run faster except to make it do less. (Here, when I say "program," I'm not talking about complex, orchestrated web apps or anything with fancy dependencies, just standalone executables in which there's a "main loop.")
Key takeaway: Don't think in terms of making a slow piece of code run faster. Instead, think in terms of making it do less.
In many cases, doing less means using a different algorithm. Then again, it may be as simple as inserting a few if-elses to check for a few trivial (but frequently encountered) "special cases" and return early, before entering a fully-generalized loop.
It may mean canonicalizing your data in some way before passing it to the main routine, so that the main routine doesn't have to include code that checks for corner cases.
The tricks are endless, but they end up with the CPU doing less, not more; and that's the key.
The "go fast do less" mantra has been a valuable one for me, paying off in many ways, in many situations, over the years. It has helped me understand performance issues in a different kind of way. I'm grateful to have been exposed to that concept early in my career. So I provide it here for you to use (or not use) as you see fit.
Maybe you received a similarly influential piece of advice early in your career? If so, please leave a comment. I'd love to hear about it.
Fortunately, I had a fabulous mentor in those days, a coder with wisdom and experience far beyond his years. The person in question was a first-class code ninja and a master circuit designer, a genius of Woz-like proportions. Silicon obeyed him the way marble obeyed Michelangelo.
When it came to code, John could do astounding things. He could optimize (and did optimize) virtually any algorithm for any situation, and do it in so little code that you'd sit there studying the printout, wondering where the heck the algorithm went! I remember John had this peculiar way of making loops vanish, for example. They'd turn into table-lookups or recursion or self-modifying code, or some combination of the three.
One day my mentor asked me what I was working on and I told him. I mentioned that I was frantically searching for a way to speed up my little program. I described a few of the things I'd tried so far. He listened intently.
When I was done talking, John gave me some of the most profound advice any programming expert has ever given me. (It was profound for me, at the time. Maybe it'll be stupid-sounding to you.)
"The CPU," he said, "runs at a certain speed. It can execute a fixed number of instructions per second, and no more. There is a finite limit to how many instructions per second it can execute. Right?"
"Right," I said.
"So there is no way, really, to make code go faster, because there is no way to make instructions execute faster. There is only such a thing as making the machine do less."
He paused for emphasis.
"To go fast," he said slowly, "do less."
To go fast, do less. Do less; go fast. Yes, of course. It makes perfect sense. There's no other way to make a program run faster except to make it do less. (Here, when I say "program," I'm not talking about complex, orchestrated web apps or anything with fancy dependencies, just standalone executables in which there's a "main loop.")
Key takeaway: Don't think in terms of making a slow piece of code run faster. Instead, think in terms of making it do less.
In many cases, doing less means using a different algorithm. Then again, it may be as simple as inserting a few if-elses to check for a few trivial (but frequently encountered) "special cases" and return early, before entering a fully-generalized loop.
It may mean canonicalizing your data in some way before passing it to the main routine, so that the main routine doesn't have to include code that checks for corner cases.
The tricks are endless, but they end up with the CPU doing less, not more; and that's the key.
The "go fast do less" mantra has been a valuable one for me, paying off in many ways, in many situations, over the years. It has helped me understand performance issues in a different kind of way. I'm grateful to have been exposed to that concept early in my career. So I provide it here for you to use (or not use) as you see fit.
Maybe you received a similarly influential piece of advice early in your career? If so, please leave a comment. I'd love to hear about it.
Saturday, March 21, 2009
Who bears responsibility for layoffs?
In these less-than-buoyant economic times, many technology companies are struggling to remain profitable. Some are struggling for their lives. When earnings turn negative, talk turns to cost-cutting. And since the single biggest cost of running a company is people (or should I say, the salaries, benefits, and miscellaneous costs associated with employees), inevitably the meat cleaver comes out. The result: Headcount reduction. Downsizing. Rightsizing. "Smartsizing." Redeployment. Restructuring. Reduction in force (RIF). Force shaping.
In non-Dilbertian terms: Layoffs.
Paradoxically, it costs a lot of money to let people go (in the U.S., at least). Time-Warner recently announced it would cut 1200 jobs. According to the company, the RIF will cost an estimated $100 million.
The true costs of a RIF to a company go well beyond the termination pay and other costs associated with getting rid of someone. The real costs include:
What if you're Sun? Or Novell? Or Vignette?
The answer is pretty simple. Responsibility for a company performance ultimately rests with executive leadership: the folks at the top.
A company's success is a team effort, obviously. No one person causes a company to succeed or fail. But strategy -- and its execution -- begin at the top. It all cascades down from there. This is why the folks with CxO after their names are paid the Big Bucks. Isn't it?
Therefore, when I see a company like Sun (which is overflowing with good technology and good people) do poorly over a protracted period of time -- going back before the current recession -- I can't help but wonder why folks like Jonathan Schwartz get to keep their jobs.
Mind you, I have nothing against Schwartz. I know someone who has worked closely with him, and by all accounts he's a really nice guy. But guess what? He has failed at his job.
The same can be said for Ron Hovsepian at Novell. I know him to be a heck of a nice guy. He's smart, he's dynamic, and his heart is in the right place. But he, too, has failed miserably at his job.
The list is long.
I don't know about you, but I think people who fail in their jobs (no matter how smart they are or how personable or how great a job they did in prior lives at other companies) need to be put on probation, then ultimately (as conditions warrant) replaced. This is how it works at the bottom. This is how it works at the middle. It needs to work that way at the top.
Sure, it happens. But it's not happening fast enough.
In non-Dilbertian terms: Layoffs.
Paradoxically, it costs a lot of money to let people go (in the U.S., at least). Time-Warner recently announced it would cut 1200 jobs. According to the company, the RIF will cost an estimated $100 million.
The true costs of a RIF to a company go well beyond the termination pay and other costs associated with getting rid of someone. The real costs include:
- Brand equity costs: How much does it hurt a company's reputation as a "good place to work" when it announces layoffs?
- Morale costs: Employees who survive the cut are often demoralized and fearful (with good reason).
- Rehiring costs: Eventually, when (and if) things turn around, some positions will need tobe refilled.
- Sales-disruption costs: Deals may fail to close, or a company may be eliminated from consideration during a procurement effort, if the company in question is perceived as "in trouble" due to a painful cost-cutting exercise involving layoffs. These days, procurement teams are justifiably "skittish." They want to avoid going with a company that might be perceived as a risky choice.
What if you're Sun? Or Novell? Or Vignette?
The answer is pretty simple. Responsibility for a company performance ultimately rests with executive leadership: the folks at the top.
A company's success is a team effort, obviously. No one person causes a company to succeed or fail. But strategy -- and its execution -- begin at the top. It all cascades down from there. This is why the folks with CxO after their names are paid the Big Bucks. Isn't it?
Therefore, when I see a company like Sun (which is overflowing with good technology and good people) do poorly over a protracted period of time -- going back before the current recession -- I can't help but wonder why folks like Jonathan Schwartz get to keep their jobs.
Mind you, I have nothing against Schwartz. I know someone who has worked closely with him, and by all accounts he's a really nice guy. But guess what? He has failed at his job.
The same can be said for Ron Hovsepian at Novell. I know him to be a heck of a nice guy. He's smart, he's dynamic, and his heart is in the right place. But he, too, has failed miserably at his job.
The list is long.
I don't know about you, but I think people who fail in their jobs (no matter how smart they are or how personable or how great a job they did in prior lives at other companies) need to be put on probation, then ultimately (as conditions warrant) replaced. This is how it works at the bottom. This is how it works at the middle. It needs to work that way at the top.
Sure, it happens. But it's not happening fast enough.
Friday, March 20, 2009

Thursday, March 19, 2009
Developers should not be allowed to work overtime
I have a very simple tip for software companies and engineering managers who want to make their developers happier and more productive (and less likely to produce buggy code). Forbid overtime.
I give this advice based primarily on what I've observed personally (and anecdotally via friends in the industry). What I've witnessed is that people who are flogged like mules either burn out, quit their jobs unexpectedly, or (worse) stay with the company, carrying a new, sour attitude.
Conversely, I've seen that developers who are encouraged to go home at quitting time tend to do a better overall job, because they know what's expected of them (i.e., finish what you're doing by 5:00) and come to work in the morning well-rested (or at least with a reasonably positive outlook compared to their counterparts at other companies who are doing 60- or 80-hour weeks).
People who know they have to leave at 5:00 (or 6:00, etc.) tend to go to extra lengths to finish whatever it is they were working on before the clock runs out. They ramp up their productivity as necessary to get work done in the time allotted. This is what you want.
Productive employees become more productive when they have to work within time constraints, because they learn time-management skills they wouldn't otherwise learn. That sounds like a tautology, but it's true.
It works in reverse as well. You find out quickly who your less-productive people are when they're under time constraints. This is valuable info if you're a manager.
The no-overtime rule tends to enforce good project-management discipline. People become realistic about how much progress can be achieved in a given length of time and set milestone dates accordingly. If delivery goals aren't met, new dates are set (assuming there's a firm no-overtime rule) and project managers assume responsibility for the initial misjudgment. (Of course, the project managers get their time estimates from the various engineering managers, so the responsibility for missing a goal actually gets cascaded down through management.)
Without a no-overtime rule, people are expected to adjust their work day as needed in order to meet milestones, and failure to meet the goal is blamed on employees rather than management (because the underlying assumption is that if you put in enough hours, you could have made the goal). Putting the onus for lateness on regular employees rather than managers only demoralizes workers and makes them less apt to deliver on future deadlines. The right thing to do (the productive thing to do, in the long run) is let managers bear responsibility for lateness -- as they should.
When I see or hear tales of people sleeping under their desk and drinking energy drinks while they bang out code at 2:00 in the morning, I know that the company in question is poorly run and will ultimately suffer (in any number of possible ways) for making (or letting) people work crazy shifts. "But," you may be saying, "what if people are putting in those hours because they truly want to?" In my experience, people with families like to be with their families. Some people take classes at night (or need to change a baby's diapers in the middle of the night), or have ailing relatives to take care of, or have any number of other outside responsibilities. Working till dawn is not an option for some people, and in my experience most people do not choose it voluntarily. There are exceptions, of course (such as with short-staffed entrepreneurs who are trying to bootstrap a new business), but as a general rule, working till 2:00 or sleeping under your desk not only reflects bad company policy but poor personal judgment as well. (Again, though, if you're a founder of a new business, you do what you have to do. But if you know what's good for you, you won't make others work that way.)
I'm sure there are some who would say that in these troubled economic times, special measures are called for. Many companies, after all, are fighting for their very lives right now. Surely workers should expect to work overtime some of the time, until the economic storm passes?
To which I say: If your situation is so desperate that you think making people work a few extra hours is going to save the company, you're in more trouble than you think. Way more.
I give this advice based primarily on what I've observed personally (and anecdotally via friends in the industry). What I've witnessed is that people who are flogged like mules either burn out, quit their jobs unexpectedly, or (worse) stay with the company, carrying a new, sour attitude.
Conversely, I've seen that developers who are encouraged to go home at quitting time tend to do a better overall job, because they know what's expected of them (i.e., finish what you're doing by 5:00) and come to work in the morning well-rested (or at least with a reasonably positive outlook compared to their counterparts at other companies who are doing 60- or 80-hour weeks).
People who know they have to leave at 5:00 (or 6:00, etc.) tend to go to extra lengths to finish whatever it is they were working on before the clock runs out. They ramp up their productivity as necessary to get work done in the time allotted. This is what you want.
Productive employees become more productive when they have to work within time constraints, because they learn time-management skills they wouldn't otherwise learn. That sounds like a tautology, but it's true.
It works in reverse as well. You find out quickly who your less-productive people are when they're under time constraints. This is valuable info if you're a manager.
The no-overtime rule tends to enforce good project-management discipline. People become realistic about how much progress can be achieved in a given length of time and set milestone dates accordingly. If delivery goals aren't met, new dates are set (assuming there's a firm no-overtime rule) and project managers assume responsibility for the initial misjudgment. (Of course, the project managers get their time estimates from the various engineering managers, so the responsibility for missing a goal actually gets cascaded down through management.)
Without a no-overtime rule, people are expected to adjust their work day as needed in order to meet milestones, and failure to meet the goal is blamed on employees rather than management (because the underlying assumption is that if you put in enough hours, you could have made the goal). Putting the onus for lateness on regular employees rather than managers only demoralizes workers and makes them less apt to deliver on future deadlines. The right thing to do (the productive thing to do, in the long run) is let managers bear responsibility for lateness -- as they should.
When I see or hear tales of people sleeping under their desk and drinking energy drinks while they bang out code at 2:00 in the morning, I know that the company in question is poorly run and will ultimately suffer (in any number of possible ways) for making (or letting) people work crazy shifts. "But," you may be saying, "what if people are putting in those hours because they truly want to?" In my experience, people with families like to be with their families. Some people take classes at night (or need to change a baby's diapers in the middle of the night), or have ailing relatives to take care of, or have any number of other outside responsibilities. Working till dawn is not an option for some people, and in my experience most people do not choose it voluntarily. There are exceptions, of course (such as with short-staffed entrepreneurs who are trying to bootstrap a new business), but as a general rule, working till 2:00 or sleeping under your desk not only reflects bad company policy but poor personal judgment as well. (Again, though, if you're a founder of a new business, you do what you have to do. But if you know what's good for you, you won't make others work that way.)
I'm sure there are some who would say that in these troubled economic times, special measures are called for. Many companies, after all, are fighting for their very lives right now. Surely workers should expect to work overtime some of the time, until the economic storm passes?
To which I say: If your situation is so desperate that you think making people work a few extra hours is going to save the company, you're in more trouble than you think. Way more.
Wednesday, March 18, 2009
Making one line of code do the work of 47
Every year or two, I go back and re-read certain papers, presentations, and book chapters that have inspired me or been the source of priceless "Aha moments." One paper that I periodically revisit is John K. Ousterhout's Scripting: Higher Level Programming for the 21st Century, written when Ousterhout was affiliated with Interwoven. (He's currently a research professor at Stanford.)
If you're not familiar with John K. Ousterhout, it might be because you don't use Tcl (Tool Command Language, the scripting language created by Ousterhout). Sun Microsystems hired Ousterhout in 1994 specifically to accelerate the development of Tcl. It turns out that Sun's CTO at the time (the person who hired Ousterhout) was Eric Schmidt. (Yes, that Eric Schmidt.) The whole story of the creation of Tcl (an interesting tale in its own right) is told by Ousterhout here.
In any case, if you haven't yet encountered Ousterhout's excellent "Scripting" paper (originally published in IEEE Computing), I recommend that you check it out. Don't be misled by the 1998 date. It's still a very relevant paper.
Rather than argue for or against scripting languages, Ousterhout lays out the philosophy (and relative benefits) of various kinds of languages and explains, often with recourse to real-world data, why certain languages are advantageous in certain situations and others are not.
Ousterhout talks about the productivity-multiplier effect of high-level languages:

This graph produced a kind of "Aha!" moment for me, because I realized (in a way I somehow hadn't, before) that scripting languages were all about code reuse; that if I could reduce the number of lines of code I write, I can (almost by definition) reduce the number of bugs I write; and that if one can accomplish an operation by calling a library method (such as the String "replace" method in JavaScript), scripted code can run at compiled-language speed, because a scripting language's built-in methods are implemented in C++ (Spidermonkey) or Java (Rhino).
If you haven't read Ousterhout's paper before, I don't want to spoil the suspense here. Suffice it to say, the paper gives a balanced account of the strengths and weaknesses of languages of all kinds; there's no language-bigotry, no theological diatribes. It's a concise and eloquent treatment of a tricky topic, and considering the year in which it was written, it's quite a prescient piece in many ways. On top of everything else, it's just plain entertaining to read -- a rarity these days, online or off-.
If you're not familiar with John K. Ousterhout, it might be because you don't use Tcl (Tool Command Language, the scripting language created by Ousterhout). Sun Microsystems hired Ousterhout in 1994 specifically to accelerate the development of Tcl. It turns out that Sun's CTO at the time (the person who hired Ousterhout) was Eric Schmidt. (Yes, that Eric Schmidt.) The whole story of the creation of Tcl (an interesting tale in its own right) is told by Ousterhout here.
In any case, if you haven't yet encountered Ousterhout's excellent "Scripting" paper (originally published in IEEE Computing), I recommend that you check it out. Don't be misled by the 1998 date. It's still a very relevant paper.
Rather than argue for or against scripting languages, Ousterhout lays out the philosophy (and relative benefits) of various kinds of languages and explains, often with recourse to real-world data, why certain languages are advantageous in certain situations and others are not.
Ousterhout talks about the productivity-multiplier effect of high-level languages:
On average, each line of code in a system programming language translates to about five machine instructions, compared to one instruction per line in assembly language (in an informal analysis of eight C files written by five different people, I found that the ratio ranged from about 3 to 7 instructions per line[7]; in a study of numerous languages Capers Jones found that for a given task, assembly languages require about 3-6 times as many lines of code as system programming languages[3]). Programmers can write roughly the same number of lines of code per year regardless of language[1], so system programming languages allow applications to be written much more quickly than assembly language.The same effect applies when going from a high-level compiled language to a scripting language, except that the multiplier effect is even greater. As Ousterhout says: "A typical statement in a scripting language executes hundreds or thousands of machine instructions." The net result is summarized in the following graph.
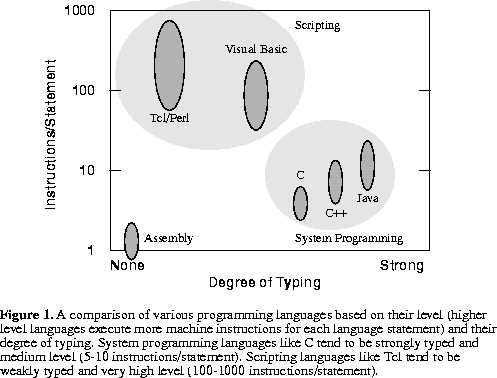
This graph produced a kind of "Aha!" moment for me, because I realized (in a way I somehow hadn't, before) that scripting languages were all about code reuse; that if I could reduce the number of lines of code I write, I can (almost by definition) reduce the number of bugs I write; and that if one can accomplish an operation by calling a library method (such as the String "replace" method in JavaScript), scripted code can run at compiled-language speed, because a scripting language's built-in methods are implemented in C++ (Spidermonkey) or Java (Rhino).
If you haven't read Ousterhout's paper before, I don't want to spoil the suspense here. Suffice it to say, the paper gives a balanced account of the strengths and weaknesses of languages of all kinds; there's no language-bigotry, no theological diatribes. It's a concise and eloquent treatment of a tricky topic, and considering the year in which it was written, it's quite a prescient piece in many ways. On top of everything else, it's just plain entertaining to read -- a rarity these days, online or off-.
Tuesday, March 17, 2009
Java as Legacy Language
Bruce Eckel (Thinking in Java) has an interesting post on The Positive Legacy of C++ and Java. I'm a sucker for articles that talk about Java and C++ as legacy languages, and this one is notable not only for the fact that it comes from a true authority (Eckel was on the C++ Standards Committee for 8 years, and saw the language design decisions take place first-hand) but for the 70-odd comments (mostly lengthy, mostly astute and non-emotional) that his post provoked.
Eckel's post is akin to a very short eulogy. I wish it had been much longer. But the fact is, Eckel has written numerous article, books, and blogs over the past five or six years outlining the weaknesses (large and small) of Java and C++, so it's not hard to find more to read on this subject.
Java is far from dead, of course. Much like COBOL, it will live on and on, eventually becoming something of an arcane specialty language mostly taught in universities.
What were (are) some of Java's biggest failings? Maybe it's more important (and constructive) to ask what its biggest successes were. To me, Java's major disruptive effect (when it arrived in the mid-1990s) was and is due to its game-changing notion of running on a virtualized machine. The idea of cleanly separating a language from underlying machine dependencies was a huge advance. In sum, the importance of Java is that it was/is not just a language but a platform.
A second pivotally important aspect of Java is that by its very design, it facilitated programming-in-the-large. The package mechanism, the orientation toward safe reuse, and the assurance of a common, stable, secure, platform-independent process space in which to run (the JVM), allowed teams of programmers to work independently to produce large applications that could take advantage of the huge advances in machine design (per Moore's Law) that occurred throughout the 1990s (without which, frankly, Java would have failed to be anything but a curiosity).
By supporting programming-in-the-large, Java made possible the huge middleware industry we see around us today. Certainly we would have had a middleware industry without Java, but it would have looked much different and come with a much different set of problems. (It would have had even more of a Rube Goldbergish quality to it than it has now.) Java popularized the notion of an application server, which by itself was a landmark development that changed the software industry.
Another outcome of Java (and C++): The notion of design patterns. The very complexity of the large systems made possible by Java and C++ demanded a new type of "best practices" knowledge around the construction of "orchestrated systems" (tm).
We owe a lot to Java, clearly, but the sheer cost of using Java for smaller-scale projects is driving the creation of new, lighter-weight languages and frameworks that offer a better impedance match with agile working styles. Going forward, it simply won't be economical to use Java for most kinds of development.
The industry hasn't quite figured out yet what the best technologies are for replacing Java in various types of development, but that's what makes things so interesting right now. Economic downturns like the one we're in tend to drive intense competition, and intense competition breeds innovation. Hence, whatever the next Big Disruption in programming turns out to be, it will probably come sooner rather than later.
One thing is for sure: If you're in the software development business, don't cling to old ways of doing development. And also, don't get too carried away thinking that something like Scrum is going to be the Bandaid that fixes your agility problems, because it may turn out that your main problem is Java itself. Keep an open mind. Try new things. Be ready when the next disruption arrives, or you may find yourself without a chair when the music stops.
Eckel's post is akin to a very short eulogy. I wish it had been much longer. But the fact is, Eckel has written numerous article, books, and blogs over the past five or six years outlining the weaknesses (large and small) of Java and C++, so it's not hard to find more to read on this subject.
Java is far from dead, of course. Much like COBOL, it will live on and on, eventually becoming something of an arcane specialty language mostly taught in universities.
What were (are) some of Java's biggest failings? Maybe it's more important (and constructive) to ask what its biggest successes were. To me, Java's major disruptive effect (when it arrived in the mid-1990s) was and is due to its game-changing notion of running on a virtualized machine. The idea of cleanly separating a language from underlying machine dependencies was a huge advance. In sum, the importance of Java is that it was/is not just a language but a platform.
A second pivotally important aspect of Java is that by its very design, it facilitated programming-in-the-large. The package mechanism, the orientation toward safe reuse, and the assurance of a common, stable, secure, platform-independent process space in which to run (the JVM), allowed teams of programmers to work independently to produce large applications that could take advantage of the huge advances in machine design (per Moore's Law) that occurred throughout the 1990s (without which, frankly, Java would have failed to be anything but a curiosity).
By supporting programming-in-the-large, Java made possible the huge middleware industry we see around us today. Certainly we would have had a middleware industry without Java, but it would have looked much different and come with a much different set of problems. (It would have had even more of a Rube Goldbergish quality to it than it has now.) Java popularized the notion of an application server, which by itself was a landmark development that changed the software industry.
Another outcome of Java (and C++): The notion of design patterns. The very complexity of the large systems made possible by Java and C++ demanded a new type of "best practices" knowledge around the construction of "orchestrated systems" (tm).
We owe a lot to Java, clearly, but the sheer cost of using Java for smaller-scale projects is driving the creation of new, lighter-weight languages and frameworks that offer a better impedance match with agile working styles. Going forward, it simply won't be economical to use Java for most kinds of development.
The industry hasn't quite figured out yet what the best technologies are for replacing Java in various types of development, but that's what makes things so interesting right now. Economic downturns like the one we're in tend to drive intense competition, and intense competition breeds innovation. Hence, whatever the next Big Disruption in programming turns out to be, it will probably come sooner rather than later.
One thing is for sure: If you're in the software development business, don't cling to old ways of doing development. And also, don't get too carried away thinking that something like Scrum is going to be the Bandaid that fixes your agility problems, because it may turn out that your main problem is Java itself. Keep an open mind. Try new things. Be ready when the next disruption arrives, or you may find yourself without a chair when the music stops.
Sunday, March 15, 2009
JWebPain
At the last JavaOne, Sun pre-announced a technology that Java developers have been wanting desperately for years: decent browser emulation in a Swing component. The demo (of something called JWebPane) got everyone pretty excited. It looked too good to be true. And now maybe it is.
Mind you, I don't have any kind of inside information to share (I wish I did) and I don't know any more than you do what happened to JWebPane. But it's been missing-in-action ever since the Big Demo. Even Sun's bloggers have gone silent on it. The last known-good Sun blog on JWebPane was Alexy Ushakov's blog of 10 December 2008. Ushakov is the tech lead on JWebPane. He hasn't blogged about it since. And neither has anyone else at Sun, from what I can determine.
I have to wonder, at this point, if JWebPane hasn't been back-burnered in favor of something more important (although I can't imagine what that might be, frankly). I'm starting to think JWebPane might actually be pre-announced a second time, at the next JavaOne.
Here's what we know so far. JWebPane is based on WebKit and (of necessity) uses JNI to glue-through to WebKit. It leverages Java2D for rendering and will support an Events API (among others). Contrary to myth, it doesn't require JavaFX. Some additional details can be seen at http://blogs.sun.com/thejavatutorials/entry/html_component, where (interestingly) the JWebPane project was described as 70% complete back in May 2008.
Some JWebPane sample code is given in this slideshow. Of course, there's no way to use the code since JWebPane isn't available for download, but at least you can see some of the basic usage patterns.
Sun has tried before to provide a degree of HTML rendering capability in various components:
Anyone who has tried to use these prior APIs for anything nontrivial knows what the limitations are. They're substantial.
Currently there are two popular substitutes for the not-yet-ready JWebPane. MozSwing is an integration of XULRunner with Swing and is quite an interesting beast in its own right. The Flying Saucer Project is quite a powerful XHTML-rendering technology, notable for its extensive support of CSS (and its lack of support for JavaScript).
MozSwing has been criticized for being heavyweight (something like 50MB), but I think we can safely assume that JWebPane, if it ever sees the light of day, won't exactly be the anorexic runway model of HTML components. It probably also won't be anyone's idea of elegant or performant (judging only from Sun's history on stuff like this), but we'll see.
If you Google around and visit some forums, you can see that developers (believing Sun's promise of nearly a year ago that JWebPane would be ready in 3 months) have held off on new projects, waiting for JWP's release. This is the tragedy that is Sun, though. Sun exuberantly pre-announces a technology that should have been introduced a decade ago, then fails to deliver on a timely basis, betraying the trust of the very developers it hopes to attract with things like JavaFX.
Let this be a case study for other vendors considering pre-announcing exciting new technologies. Be ready to deliver, or else don't pre-announce. If you pre-announce and don't come through, you've simultaneously destroyed your own credibility and antagonized potential customers. And if you're in the software business and the people you've antagonized are developers, you've done yourself a double disservice. (Generally speaking, the last people you want to antagonize, if you're looking to build mindshare, are developers.)
Let's sum it up this way: When in doubt, don't pre-announce. Instead, keep your mouth wide shut.
Mind you, I don't have any kind of inside information to share (I wish I did) and I don't know any more than you do what happened to JWebPane. But it's been missing-in-action ever since the Big Demo. Even Sun's bloggers have gone silent on it. The last known-good Sun blog on JWebPane was Alexy Ushakov's blog of 10 December 2008. Ushakov is the tech lead on JWebPane. He hasn't blogged about it since. And neither has anyone else at Sun, from what I can determine.
I have to wonder, at this point, if JWebPane hasn't been back-burnered in favor of something more important (although I can't imagine what that might be, frankly). I'm starting to think JWebPane might actually be pre-announced a second time, at the next JavaOne.
Here's what we know so far. JWebPane is based on WebKit and (of necessity) uses JNI to glue-through to WebKit. It leverages Java2D for rendering and will support an Events API (among others). Contrary to myth, it doesn't require JavaFX. Some additional details can be seen at http://blogs.sun.com/thejavatutorials/entry/html_component, where (interestingly) the JWebPane project was described as 70% complete back in May 2008.
Some JWebPane sample code is given in this slideshow. Of course, there's no way to use the code since JWebPane isn't available for download, but at least you can see some of the basic usage patterns.
Sun has tried before to provide a degree of HTML rendering capability in various components:
Anyone who has tried to use these prior APIs for anything nontrivial knows what the limitations are. They're substantial.
Currently there are two popular substitutes for the not-yet-ready JWebPane. MozSwing is an integration of XULRunner with Swing and is quite an interesting beast in its own right. The Flying Saucer Project is quite a powerful XHTML-rendering technology, notable for its extensive support of CSS (and its lack of support for JavaScript).
MozSwing has been criticized for being heavyweight (something like 50MB), but I think we can safely assume that JWebPane, if it ever sees the light of day, won't exactly be the anorexic runway model of HTML components. It probably also won't be anyone's idea of elegant or performant (judging only from Sun's history on stuff like this), but we'll see.
If you Google around and visit some forums, you can see that developers (believing Sun's promise of nearly a year ago that JWebPane would be ready in 3 months) have held off on new projects, waiting for JWP's release. This is the tragedy that is Sun, though. Sun exuberantly pre-announces a technology that should have been introduced a decade ago, then fails to deliver on a timely basis, betraying the trust of the very developers it hopes to attract with things like JavaFX.
Let this be a case study for other vendors considering pre-announcing exciting new technologies. Be ready to deliver, or else don't pre-announce. If you pre-announce and don't come through, you've simultaneously destroyed your own credibility and antagonized potential customers. And if you're in the software business and the people you've antagonized are developers, you've done yourself a double disservice. (Generally speaking, the last people you want to antagonize, if you're looking to build mindshare, are developers.)
Let's sum it up this way: When in doubt, don't pre-announce. Instead, keep your mouth wide shut.
Saturday, March 14, 2009
JMenu's 433 methods
I've referred, in previous posts, to the fact that Java's JMenu class has 433 methods. I pick on the JMenu class sometimes when I need a convenient example of the piggishness of Java or inheritance gone to an extreme. An alphabetized list of all 433 of JMenu's methods is shown below.
Please note that JMenu is at the bottom of a 7-level-deep inheritance chain. Hence, it inherits most of its methods. All of the inherited methods are shown below along with JMenu's own declared methods, which come at the bottom.
I explain how this list was generated (using JavaScript, in Firefox) at the end of the list. Please scroll down.
java.awt.Component.action(java.awt.Event,java.lang.Object)
java.awt.Component.add(java.awt.PopupMenu)
java.awt.Component.addComponentListener(java.awt.event.ComponentListener)
java.awt.Component.addFocusListener(java.awt.event.FocusListener)
java.awt.Component.addHierarchyBoundsListener(java.awt.event.HierarchyBoundsListener)
java.awt.Component.addHierarchyListener(java.awt.event.HierarchyListener)
java.awt.Component.addInputMethodListener(java.awt.event.InputMethodListener)
java.awt.Component.addKeyListener(java.awt.event.KeyListener)
java.awt.Component.addMouseListener(java.awt.event.MouseListener)
java.awt.Component.addMouseMotionListener(java.awt.event.MouseMotionListener)
java.awt.Component.addMouseWheelListener(java.awt.event.MouseWheelListener)
java.awt.Component.bounds()
java.awt.Component.checkImage(java.awt.Image,int,int,java.awt.image.ImageObserver)
java.awt.Component.checkImage(java.awt.Image,java.awt.image.ImageObserver)
java.awt.Component.contains(java.awt.Point)
java.awt.Component.createImage(int,int)
java.awt.Component.createImage(java.awt.image.ImageProducer)
java.awt.Component.createVolatileImage(int,int)
java.awt.Component.createVolatileImage(int,int,java.awt.ImageCapabilities)
java.awt.Component.dispatchEvent(java.awt.AWTEvent)
java.awt.Component.enable(boolean)
java.awt.Component.enableInputMethods(boolean)
java.awt.Component.firePropertyChange(java.lang.String,byte,byte)
java.awt.Component.firePropertyChange(java.lang.String,double,double)
java.awt.Component.firePropertyChange(java.lang.String,float,float)
java.awt.Component.firePropertyChange(java.lang.String,long,long)
java.awt.Component.firePropertyChange(java.lang.String,short,short)
java.awt.Component.getBackground()
java.awt.Component.getBounds()
java.awt.Component.getColorModel()
java.awt.Component.getComponentListeners()
java.awt.Component.getComponentOrientation()
java.awt.Component.getCursor()
java.awt.Component.getDropTarget()
java.awt.Component.getFocusCycleRootAncestor()
java.awt.Component.getFocusListeners()
java.awt.Component.getFocusTraversalKeysEnabled()
java.awt.Component.getFont()
java.awt.Component.getForeground()
java.awt.Component.getGraphicsConfiguration()
java.awt.Component.getHierarchyBoundsListeners()
java.awt.Component.getHierarchyListeners()
java.awt.Component.getIgnoreRepaint()
java.awt.Component.getInputContext()
java.awt.Component.getInputMethodListeners()
java.awt.Component.getInputMethodRequests()
java.awt.Component.getKeyListeners()
java.awt.Component.getLocale()
java.awt.Component.getLocation()
java.awt.Component.getLocationOnScreen()
java.awt.Component.getMouseListeners()
java.awt.Component.getMouseMotionListeners()
java.awt.Component.getMousePosition()
java.awt.Component.getMouseWheelListeners()
java.awt.Component.getName()
java.awt.Component.getParent()
java.awt.Component.getPeer()
java.awt.Component.getPropertyChangeListeners()
java.awt.Component.getPropertyChangeListeners(java.lang.String)
java.awt.Component.getSize()
java.awt.Component.getToolkit()
java.awt.Component.getTreeLock()
java.awt.Component.gotFocus(java.awt.Event,java.lang.Object)
java.awt.Component.handleEvent(java.awt.Event)
java.awt.Component.hasFocus()
java.awt.Component.hide()
java.awt.Component.inside(int,int)
java.awt.Component.isBackgroundSet()
java.awt.Component.isCursorSet()
java.awt.Component.isDisplayable()
java.awt.Component.isEnabled()
java.awt.Component.isFocusOwner()
java.awt.Component.isFocusTraversable()
java.awt.Component.isFocusable()
java.awt.Component.isFontSet()
java.awt.Component.isForegroundSet()
java.awt.Component.isLightweight()
java.awt.Component.isMaximumSizeSet()
java.awt.Component.isMinimumSizeSet()
java.awt.Component.isPreferredSizeSet()
java.awt.Component.isShowing()
java.awt.Component.isValid()
java.awt.Component.isVisible()
java.awt.Component.keyDown(java.awt.Event,int)
java.awt.Component.keyUp(java.awt.Event,int)
java.awt.Component.list()
java.awt.Component.list(java.io.PrintStream)
java.awt.Component.list(java.io.PrintWriter)
java.awt.Component.location()
java.awt.Component.lostFocus(java.awt.Event,java.lang.Object)
java.awt.Component.mouseDown(java.awt.Event,int,int)
java.awt.Component.mouseDrag(java.awt.Event,int,int)
java.awt.Component.mouseEnter(java.awt.Event,int,int)
java.awt.Component.mouseExit(java.awt.Event,int,int)
java.awt.Component.mouseMove(java.awt.Event,int,int)
java.awt.Component.mouseUp(java.awt.Event,int,int)
java.awt.Component.move(int,int)
java.awt.Component.nextFocus()
java.awt.Component.paintAll(java.awt.Graphics)
java.awt.Component.postEvent(java.awt.Event)
java.awt.Component.prepareImage(java.awt.Image,int,int,java.awt.image.ImageObserver)
java.awt.Component.prepareImage(java.awt.Image,java.awt.image.ImageObserver)
java.awt.Component.remove(java.awt.MenuComponent)
java.awt.Component.removeComponentListener(java.awt.event.ComponentListener)
java.awt.Component.removeFocusListener(java.awt.event.FocusListener)
java.awt.Component.removeHierarchyBoundsListener(java.awt.event.HierarchyBoundsListener)
java.awt.Component.removeHierarchyListener(java.awt.event.HierarchyListener)
java.awt.Component.removeInputMethodListener(java.awt.event.InputMethodListener)
java.awt.Component.removeKeyListener(java.awt.event.KeyListener)
java.awt.Component.removeMouseListener(java.awt.event.MouseListener)
java.awt.Component.removeMouseMotionListener(java.awt.event.MouseMotionListener)
java.awt.Component.removeMouseWheelListener(java.awt.event.MouseWheelListener)
java.awt.Component.removePropertyChangeListener(java.beans.PropertyChangeListener)
java.awt.Component.removePropertyChangeListener(java.lang.String,java.beans.PropertyChangeListener)
java.awt.Component.repaint()
java.awt.Component.repaint(int,int,int,int)
java.awt.Component.repaint(long)
java.awt.Component.resize(int,int)
java.awt.Component.resize(java.awt.Dimension)
java.awt.Component.setBounds(int,int,int,int)
java.awt.Component.setBounds(java.awt.Rectangle)
java.awt.Component.setCursor(java.awt.Cursor)
java.awt.Component.setDropTarget(java.awt.dnd.DropTarget)
java.awt.Component.setFocusTraversalKeysEnabled(boolean)
java.awt.Component.setFocusable(boolean)
java.awt.Component.setIgnoreRepaint(boolean)
java.awt.Component.setLocale(java.util.Locale)
java.awt.Component.setLocation(int,int)
java.awt.Component.setLocation(java.awt.Point)
java.awt.Component.setName(java.lang.String)
java.awt.Component.setSize(int,int)
java.awt.Component.setSize(java.awt.Dimension)
java.awt.Component.show()
java.awt.Component.show(boolean)
java.awt.Component.size()
java.awt.Component.toString()
java.awt.Component.transferFocus()
java.awt.Component.transferFocusUpCycle()
java.awt.Container.add(java.awt.Component,java.lang.Object)
java.awt.Container.add(java.awt.Component,java.lang.Object,int)
java.awt.Container.add(java.lang.String,java.awt.Component)
java.awt.Container.addContainerListener(java.awt.event.ContainerListener)
java.awt.Container.addPropertyChangeListener(java.beans.PropertyChangeListener)
java.awt.Container.addPropertyChangeListener(java.lang.String,java.beans.PropertyChangeListener)
java.awt.Container.areFocusTraversalKeysSet(int)
java.awt.Container.countComponents()
java.awt.Container.deliverEvent(java.awt.Event)
java.awt.Container.doLayout()
java.awt.Container.findComponentAt(int,int)
java.awt.Container.findComponentAt(java.awt.Point)
java.awt.Container.getComponent(int)
java.awt.Container.getComponentAt(int,int)
java.awt.Container.getComponentAt(java.awt.Point)
java.awt.Container.getComponentCount()
java.awt.Container.getComponentZOrder(java.awt.Component)
java.awt.Container.getComponents()
java.awt.Container.getContainerListeners()
java.awt.Container.getFocusTraversalKeys(int)
java.awt.Container.getFocusTraversalPolicy()
java.awt.Container.getLayout()
java.awt.Container.getMousePosition(boolean)
java.awt.Container.insets()
java.awt.Container.invalidate()
java.awt.Container.isAncestorOf(java.awt.Component)
java.awt.Container.isFocusCycleRoot()
java.awt.Container.isFocusCycleRoot(java.awt.Container)
java.awt.Container.isFocusTraversalPolicyProvider()
java.awt.Container.isFocusTraversalPolicySet()
java.awt.Container.layout()
java.awt.Container.list(java.io.PrintStream,int)
java.awt.Container.list(java.io.PrintWriter,int)
java.awt.Container.locate(int,int)
java.awt.Container.minimumSize()
java.awt.Container.paintComponents(java.awt.Graphics)
java.awt.Container.preferredSize()
java.awt.Container.printComponents(java.awt.Graphics)
java.awt.Container.removeContainerListener(java.awt.event.ContainerListener)
java.awt.Container.setComponentZOrder(java.awt.Component,int)
java.awt.Container.setFocusCycleRoot(boolean)
java.awt.Container.setFocusTraversalPolicy(java.awt.FocusTraversalPolicy)
java.awt.Container.setFocusTraversalPolicyProvider(boolean)
java.awt.Container.transferFocusBackward()
java.awt.Container.transferFocusDownCycle()
java.awt.Container.validate()
java.lang.Object.equals(java.lang.Object)
java.lang.Object.getClass()
java.lang.Object.hashCode()
java.lang.Object.notify()
java.lang.Object.notifyAll()
java.lang.Object.wait()
java.lang.Object.wait(long)
java.lang.Object.wait(long,int)
javax.swing.AbstractButton.addActionListener(java.awt.event.ActionListener)
javax.swing.AbstractButton.addChangeListener(javax.swing.event.ChangeListener)
javax.swing.AbstractButton.addItemListener(java.awt.event.ItemListener)
javax.swing.AbstractButton.doClick()
javax.swing.AbstractButton.getAction()
javax.swing.AbstractButton.getActionCommand()
javax.swing.AbstractButton.getActionListeners()
javax.swing.AbstractButton.getChangeListeners()
javax.swing.AbstractButton.getDisabledIcon()
javax.swing.AbstractButton.getDisabledSelectedIcon()
javax.swing.AbstractButton.getDisplayedMnemonicIndex()
javax.swing.AbstractButton.getHideActionText()
javax.swing.AbstractButton.getHorizontalAlignment()
javax.swing.AbstractButton.getHorizontalTextPosition()
javax.swing.AbstractButton.getIcon()
javax.swing.AbstractButton.getIconTextGap()
javax.swing.AbstractButton.getItemListeners()
javax.swing.AbstractButton.getLabel()
javax.swing.AbstractButton.getMargin()
javax.swing.AbstractButton.getMnemonic()
javax.swing.AbstractButton.getModel()
javax.swing.AbstractButton.getMultiClickThreshhold()
javax.swing.AbstractButton.getPressedIcon()
javax.swing.AbstractButton.getRolloverIcon()
javax.swing.AbstractButton.getRolloverSelectedIcon()
javax.swing.AbstractButton.getSelectedIcon()
javax.swing.AbstractButton.getSelectedObjects()
javax.swing.AbstractButton.getText()
javax.swing.AbstractButton.getUI()
javax.swing.AbstractButton.getVerticalAlignment()
javax.swing.AbstractButton.getVerticalTextPosition()
javax.swing.AbstractButton.imageUpdate(java.awt.Image,int,int,int,int,int)
javax.swing.AbstractButton.isBorderPainted()
javax.swing.AbstractButton.isContentAreaFilled()
javax.swing.AbstractButton.isFocusPainted()
javax.swing.AbstractButton.isRolloverEnabled()
javax.swing.AbstractButton.removeActionListener(java.awt.event.ActionListener)
javax.swing.AbstractButton.removeChangeListener(javax.swing.event.ChangeListener)
javax.swing.AbstractButton.removeItemListener(java.awt.event.ItemListener)
javax.swing.AbstractButton.removeNotify()
javax.swing.AbstractButton.setAction(javax.swing.Action)
javax.swing.AbstractButton.setActionCommand(java.lang.String)
javax.swing.AbstractButton.setBorderPainted(boolean)
javax.swing.AbstractButton.setContentAreaFilled(boolean)
javax.swing.AbstractButton.setDisabledIcon(javax.swing.Icon)
javax.swing.AbstractButton.setDisabledSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setDisplayedMnemonicIndex(int)
javax.swing.AbstractButton.setFocusPainted(boolean)
javax.swing.AbstractButton.setHideActionText(boolean)
javax.swing.AbstractButton.setHorizontalAlignment(int)
javax.swing.AbstractButton.setHorizontalTextPosition(int)
javax.swing.AbstractButton.setIcon(javax.swing.Icon)
javax.swing.AbstractButton.setIconTextGap(int)
javax.swing.AbstractButton.setLabel(java.lang.String)
javax.swing.AbstractButton.setLayout(java.awt.LayoutManager)
javax.swing.AbstractButton.setMargin(java.awt.Insets)
javax.swing.AbstractButton.setMnemonic(char)
javax.swing.AbstractButton.setMnemonic(int)
javax.swing.AbstractButton.setMultiClickThreshhold(long)
javax.swing.AbstractButton.setPressedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setRolloverEnabled(boolean)
javax.swing.AbstractButton.setRolloverIcon(javax.swing.Icon)
javax.swing.AbstractButton.setRolloverSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setText(java.lang.String)
javax.swing.AbstractButton.setUI(javax.swing.plaf.ButtonUI)
javax.swing.AbstractButton.setVerticalAlignment(int)
javax.swing.AbstractButton.setVerticalTextPosition(int)
javax.swing.JComponent.addAncestorListener(javax.swing.event.AncestorListener)
javax.swing.JComponent.addNotify()
javax.swing.JComponent.addVetoableChangeListener(java.beans.VetoableChangeListener)
javax.swing.JComponent.computeVisibleRect(java.awt.Rectangle)
javax.swing.JComponent.contains(int,int)
javax.swing.JComponent.createToolTip()
javax.swing.JComponent.disable()
javax.swing.JComponent.enable()
javax.swing.JComponent.firePropertyChange(java.lang.String,boolean,boolean)
javax.swing.JComponent.firePropertyChange(java.lang.String,char,char)
javax.swing.JComponent.firePropertyChange(java.lang.String,int,int)
javax.swing.JComponent.getActionForKeyStroke(javax.swing.KeyStroke)
javax.swing.JComponent.getActionMap()
javax.swing.JComponent.getAlignmentX()
javax.swing.JComponent.getAlignmentY()
javax.swing.JComponent.getAncestorListeners()
javax.swing.JComponent.getAutoscrolls()
javax.swing.JComponent.getBaseline(int,int)
javax.swing.JComponent.getBaselineResizeBehavior()
javax.swing.JComponent.getBorder()
javax.swing.JComponent.getBounds(java.awt.Rectangle)
javax.swing.JComponent.getClientProperty(java.lang.Object)
javax.swing.JComponent.getComponentPopupMenu()
javax.swing.JComponent.getConditionForKeyStroke(javax.swing.KeyStroke)
javax.swing.JComponent.getDebugGraphicsOptions()
javax.swing.JComponent.getDefaultLocale()
javax.swing.JComponent.getFontMetrics(java.awt.Font)
javax.swing.JComponent.getGraphics()
javax.swing.JComponent.getHeight()
javax.swing.JComponent.getInheritsPopupMenu()
javax.swing.JComponent.getInputMap()
javax.swing.JComponent.getInputMap(int)
javax.swing.JComponent.getInputVerifier()
javax.swing.JComponent.getInsets()
javax.swing.JComponent.getInsets(java.awt.Insets)
javax.swing.JComponent.getListeners(java.lang.Class)
javax.swing.JComponent.getLocation(java.awt.Point)
javax.swing.JComponent.getMaximumSize()
javax.swing.JComponent.getMinimumSize()
javax.swing.JComponent.getNextFocusableComponent()
javax.swing.JComponent.getPopupLocation(java.awt.event.MouseEvent)
javax.swing.JComponent.getPreferredSize()
javax.swing.JComponent.getRegisteredKeyStrokes()
javax.swing.JComponent.getRootPane()
javax.swing.JComponent.getSize(java.awt.Dimension)
javax.swing.JComponent.getToolTipLocation(java.awt.event.MouseEvent)
javax.swing.JComponent.getToolTipText()
javax.swing.JComponent.getToolTipText(java.awt.event.MouseEvent)
javax.swing.JComponent.getTopLevelAncestor()
javax.swing.JComponent.getTransferHandler()
javax.swing.JComponent.getVerifyInputWhenFocusTarget()
javax.swing.JComponent.getVetoableChangeListeners()
javax.swing.JComponent.getVisibleRect()
javax.swing.JComponent.getWidth()
javax.swing.JComponent.getX()
javax.swing.JComponent.getY()
javax.swing.JComponent.grabFocus()
javax.swing.JComponent.isDoubleBuffered()
javax.swing.JComponent.isLightweightComponent(java.awt.Component)
javax.swing.JComponent.isManagingFocus()
javax.swing.JComponent.isOpaque()
javax.swing.JComponent.isOptimizedDrawingEnabled()
javax.swing.JComponent.isPaintingForPrint()
javax.swing.JComponent.isPaintingTile()
javax.swing.JComponent.isRequestFocusEnabled()
javax.swing.JComponent.isValidateRoot()
javax.swing.JComponent.paint(java.awt.Graphics)
javax.swing.JComponent.paintImmediately(int,int,int,int)
javax.swing.JComponent.paintImmediately(java.awt.Rectangle)
javax.swing.JComponent.print(java.awt.Graphics)
javax.swing.JComponent.printAll(java.awt.Graphics)
javax.swing.JComponent.putClientProperty(java.lang.Object,java.lang.Object)
javax.swing.JComponent.registerKeyboardAction(java.awt.event.ActionListener,java.lang.String,javax.swing.KeyStroke,int)
javax.swing.JComponent.registerKeyboardAction(java.awt.event.ActionListener,javax.swing.KeyStroke,int)
javax.swing.JComponent.removeAncestorListener(javax.swing.event.AncestorListener)
javax.swing.JComponent.removeVetoableChangeListener(java.beans.VetoableChangeListener)
javax.swing.JComponent.repaint(java.awt.Rectangle)
javax.swing.JComponent.repaint(long,int,int,int,int)
javax.swing.JComponent.requestDefaultFocus()
javax.swing.JComponent.requestFocus()
javax.swing.JComponent.requestFocus(boolean)
javax.swing.JComponent.requestFocusInWindow()
javax.swing.JComponent.resetKeyboardActions()
javax.swing.JComponent.reshape(int,int,int,int)
javax.swing.JComponent.revalidate()
javax.swing.JComponent.scrollRectToVisible(java.awt.Rectangle)
javax.swing.JComponent.setActionMap(javax.swing.ActionMap)
javax.swing.JComponent.setAlignmentX(float)
javax.swing.JComponent.setAlignmentY(float)
javax.swing.JComponent.setAutoscrolls(boolean)
javax.swing.JComponent.setBackground(java.awt.Color)
javax.swing.JComponent.setBorder(javax.swing.border.Border)
javax.swing.JComponent.setComponentPopupMenu(javax.swing.JPopupMenu)
javax.swing.JComponent.setDebugGraphicsOptions(int)
javax.swing.JComponent.setDefaultLocale(java.util.Locale)
javax.swing.JComponent.setDoubleBuffered(boolean)
javax.swing.JComponent.setFocusTraversalKeys(int,java.util.Set)
javax.swing.JComponent.setFont(java.awt.Font)
javax.swing.JComponent.setForeground(java.awt.Color)
javax.swing.JComponent.setInheritsPopupMenu(boolean)
javax.swing.JComponent.setInputMap(int,javax.swing.InputMap)
javax.swing.JComponent.setInputVerifier(javax.swing.InputVerifier)
javax.swing.JComponent.setMaximumSize(java.awt.Dimension)
javax.swing.JComponent.setMinimumSize(java.awt.Dimension)
javax.swing.JComponent.setNextFocusableComponent(java.awt.Component)
javax.swing.JComponent.setOpaque(boolean)
javax.swing.JComponent.setPreferredSize(java.awt.Dimension)
javax.swing.JComponent.setRequestFocusEnabled(boolean)
javax.swing.JComponent.setToolTipText(java.lang.String)
javax.swing.JComponent.setTransferHandler(javax.swing.TransferHandler)
javax.swing.JComponent.setVerifyInputWhenFocusTarget(boolean)
javax.swing.JComponent.setVisible(boolean)
javax.swing.JComponent.unregisterKeyboardAction(javax.swing.KeyStroke)
javax.swing.JComponent.update(java.awt.Graphics)
javax.swing.JMenu.add(java.awt.Component)
javax.swing.JMenu.add(java.awt.Component,int)
javax.swing.JMenu.add(java.lang.String)
javax.swing.JMenu.add(javax.swing.Action)
javax.swing.JMenu.add(javax.swing.JMenuItem)
javax.swing.JMenu.addMenuListener(javax.swing.event.MenuListener)
javax.swing.JMenu.addSeparator()
javax.swing.JMenu.applyComponentOrientation(java.awt.ComponentOrientation)
javax.swing.JMenu.doClick(int)
javax.swing.JMenu.getAccessibleContext()
javax.swing.JMenu.getComponent()
javax.swing.JMenu.getDelay()
javax.swing.JMenu.getItem(int)
javax.swing.JMenu.getItemCount()
javax.swing.JMenu.getMenuComponent(int)
javax.swing.JMenu.getMenuComponentCount()
javax.swing.JMenu.getMenuComponents()
javax.swing.JMenu.getMenuListeners()
javax.swing.JMenu.getPopupMenu()
javax.swing.JMenu.getSubElements()
javax.swing.JMenu.getUIClassID()
javax.swing.JMenu.insert(java.lang.String,int)
javax.swing.JMenu.insert(javax.swing.Action,int)
javax.swing.JMenu.insert(javax.swing.JMenuItem,int)
javax.swing.JMenu.insertSeparator(int)
javax.swing.JMenu.isMenuComponent(java.awt.Component)
javax.swing.JMenu.isPopupMenuVisible()
javax.swing.JMenu.isSelected()
javax.swing.JMenu.isTearOff()
javax.swing.JMenu.isTopLevelMenu()
javax.swing.JMenu.menuSelectionChanged(boolean)
javax.swing.JMenu.remove(int)
javax.swing.JMenu.remove(java.awt.Component)
javax.swing.JMenu.remove(javax.swing.JMenuItem)
javax.swing.JMenu.removeAll()
javax.swing.JMenu.removeMenuListener(javax.swing.event.MenuListener)
javax.swing.JMenu.setAccelerator(javax.swing.KeyStroke)
javax.swing.JMenu.setComponentOrientation(java.awt.ComponentOrientation)
javax.swing.JMenu.setDelay(int)
javax.swing.JMenu.setMenuLocation(int,int)
javax.swing.JMenu.setModel(javax.swing.ButtonModel)
javax.swing.JMenu.setPopupMenuVisible(boolean)
javax.swing.JMenu.setSelected(boolean)
javax.swing.JMenu.updateUI()
javax.swing.JMenuItem.addMenuDragMouseListener(javax.swing.event.MenuDragMouseListener)
javax.swing.JMenuItem.addMenuKeyListener(javax.swing.event.MenuKeyListener)
javax.swing.JMenuItem.getAccelerator()
javax.swing.JMenuItem.getMenuDragMouseListeners()
javax.swing.JMenuItem.getMenuKeyListeners()
javax.swing.JMenuItem.isArmed()
javax.swing.JMenuItem.processKeyEvent(java.awt.event.KeyEvent,javax.swing.MenuElement[],javax.swing.MenuSelectionManager)
javax.swing.JMenuItem.processMenuDragMouseEvent(javax.swing.event.MenuDragMouseEvent)
javax.swing.JMenuItem.processMenuKeyEvent(javax.swing.event.MenuKeyEvent)
javax.swing.JMenuItem.processMouseEvent(java.awt.event.MouseEvent,javax.swing.MenuElement[],javax.swing.MenuSelectionManager)
javax.swing.JMenuItem.removeMenuDragMouseListener(javax.swing.event.MenuDragMouseListener)
javax.swing.JMenuItem.removeMenuKeyListener(javax.swing.event.MenuKeyListener)
javax.swing.JMenuItem.setArmed(boolean)
javax.swing.JMenuItem.setEnabled(boolean)
javax.swing.JMenuItem.setUI(javax.swing.plaf.MenuItemUI)
How This List Was Generated
I ran the following lines of JavaScript in my Firebug console:
jmenu = new Packages.javax.swing.JMenu( );
methods = jmenu.getClass( ).getMethods( );
r = /j[^( ]+\([^)]*\)/; // match just the method
for (var i = 0,
jsArray=[],
name = ""; i < methods.length; i++ ) {
name = methods[ i ].toString( );
jsArray.push( name.match( r )[ 0 ] );
}
markup = jsArray.sort( ).join( "<br/>" );
document.body.innerHTML = markup;
The key thing to understand is that you can call Java from JavaScript, in Firefox, using the Packages syntax (as shown above). Security restrictions will keep you from doing anything too interesting with scripted Java, but it's noteworthy that you can at least instantiate Java objects, including Swing objects, this way.
BTW, if you find a Java class that has more than 433 methods (clue: I do know of one more Swing class that has > 433 methods), let me know what it is. I'll credit you here.
Please note that JMenu is at the bottom of a 7-level-deep inheritance chain. Hence, it inherits most of its methods. All of the inherited methods are shown below along with JMenu's own declared methods, which come at the bottom.
I explain how this list was generated (using JavaScript, in Firefox) at the end of the list. Please scroll down.
java.awt.Component.action(java.awt.Event,java.lang.Object)
java.awt.Component.add(java.awt.PopupMenu)
java.awt.Component.addComponentListener(java.awt.event.ComponentListener)
java.awt.Component.addFocusListener(java.awt.event.FocusListener)
java.awt.Component.addHierarchyBoundsListener(java.awt.event.HierarchyBoundsListener)
java.awt.Component.addHierarchyListener(java.awt.event.HierarchyListener)
java.awt.Component.addInputMethodListener(java.awt.event.InputMethodListener)
java.awt.Component.addKeyListener(java.awt.event.KeyListener)
java.awt.Component.addMouseListener(java.awt.event.MouseListener)
java.awt.Component.addMouseMotionListener(java.awt.event.MouseMotionListener)
java.awt.Component.addMouseWheelListener(java.awt.event.MouseWheelListener)
java.awt.Component.bounds()
java.awt.Component.checkImage(java.awt.Image,int,int,java.awt.image.ImageObserver)
java.awt.Component.checkImage(java.awt.Image,java.awt.image.ImageObserver)
java.awt.Component.contains(java.awt.Point)
java.awt.Component.createImage(int,int)
java.awt.Component.createImage(java.awt.image.ImageProducer)
java.awt.Component.createVolatileImage(int,int)
java.awt.Component.createVolatileImage(int,int,java.awt.ImageCapabilities)
java.awt.Component.dispatchEvent(java.awt.AWTEvent)
java.awt.Component.enable(boolean)
java.awt.Component.enableInputMethods(boolean)
java.awt.Component.firePropertyChange(java.lang.String,byte,byte)
java.awt.Component.firePropertyChange(java.lang.String,double,double)
java.awt.Component.firePropertyChange(java.lang.String,float,float)
java.awt.Component.firePropertyChange(java.lang.String,long,long)
java.awt.Component.firePropertyChange(java.lang.String,short,short)
java.awt.Component.getBackground()
java.awt.Component.getBounds()
java.awt.Component.getColorModel()
java.awt.Component.getComponentListeners()
java.awt.Component.getComponentOrientation()
java.awt.Component.getCursor()
java.awt.Component.getDropTarget()
java.awt.Component.getFocusCycleRootAncestor()
java.awt.Component.getFocusListeners()
java.awt.Component.getFocusTraversalKeysEnabled()
java.awt.Component.getFont()
java.awt.Component.getForeground()
java.awt.Component.getGraphicsConfiguration()
java.awt.Component.getHierarchyBoundsListeners()
java.awt.Component.getHierarchyListeners()
java.awt.Component.getIgnoreRepaint()
java.awt.Component.getInputContext()
java.awt.Component.getInputMethodListeners()
java.awt.Component.getInputMethodRequests()
java.awt.Component.getKeyListeners()
java.awt.Component.getLocale()
java.awt.Component.getLocation()
java.awt.Component.getLocationOnScreen()
java.awt.Component.getMouseListeners()
java.awt.Component.getMouseMotionListeners()
java.awt.Component.getMousePosition()
java.awt.Component.getMouseWheelListeners()
java.awt.Component.getName()
java.awt.Component.getParent()
java.awt.Component.getPeer()
java.awt.Component.getPropertyChangeListeners()
java.awt.Component.getPropertyChangeListeners(java.lang.String)
java.awt.Component.getSize()
java.awt.Component.getToolkit()
java.awt.Component.getTreeLock()
java.awt.Component.gotFocus(java.awt.Event,java.lang.Object)
java.awt.Component.handleEvent(java.awt.Event)
java.awt.Component.hasFocus()
java.awt.Component.hide()
java.awt.Component.inside(int,int)
java.awt.Component.isBackgroundSet()
java.awt.Component.isCursorSet()
java.awt.Component.isDisplayable()
java.awt.Component.isEnabled()
java.awt.Component.isFocusOwner()
java.awt.Component.isFocusTraversable()
java.awt.Component.isFocusable()
java.awt.Component.isFontSet()
java.awt.Component.isForegroundSet()
java.awt.Component.isLightweight()
java.awt.Component.isMaximumSizeSet()
java.awt.Component.isMinimumSizeSet()
java.awt.Component.isPreferredSizeSet()
java.awt.Component.isShowing()
java.awt.Component.isValid()
java.awt.Component.isVisible()
java.awt.Component.keyDown(java.awt.Event,int)
java.awt.Component.keyUp(java.awt.Event,int)
java.awt.Component.list()
java.awt.Component.list(java.io.PrintStream)
java.awt.Component.list(java.io.PrintWriter)
java.awt.Component.location()
java.awt.Component.lostFocus(java.awt.Event,java.lang.Object)
java.awt.Component.mouseDown(java.awt.Event,int,int)
java.awt.Component.mouseDrag(java.awt.Event,int,int)
java.awt.Component.mouseEnter(java.awt.Event,int,int)
java.awt.Component.mouseExit(java.awt.Event,int,int)
java.awt.Component.mouseMove(java.awt.Event,int,int)
java.awt.Component.mouseUp(java.awt.Event,int,int)
java.awt.Component.move(int,int)
java.awt.Component.nextFocus()
java.awt.Component.paintAll(java.awt.Graphics)
java.awt.Component.postEvent(java.awt.Event)
java.awt.Component.prepareImage(java.awt.Image,int,int,java.awt.image.ImageObserver)
java.awt.Component.prepareImage(java.awt.Image,java.awt.image.ImageObserver)
java.awt.Component.remove(java.awt.MenuComponent)
java.awt.Component.removeComponentListener(java.awt.event.ComponentListener)
java.awt.Component.removeFocusListener(java.awt.event.FocusListener)
java.awt.Component.removeHierarchyBoundsListener(java.awt.event.HierarchyBoundsListener)
java.awt.Component.removeHierarchyListener(java.awt.event.HierarchyListener)
java.awt.Component.removeInputMethodListener(java.awt.event.InputMethodListener)
java.awt.Component.removeKeyListener(java.awt.event.KeyListener)
java.awt.Component.removeMouseListener(java.awt.event.MouseListener)
java.awt.Component.removeMouseMotionListener(java.awt.event.MouseMotionListener)
java.awt.Component.removeMouseWheelListener(java.awt.event.MouseWheelListener)
java.awt.Component.removePropertyChangeListener(java.beans.PropertyChangeListener)
java.awt.Component.removePropertyChangeListener(java.lang.String,java.beans.PropertyChangeListener)
java.awt.Component.repaint()
java.awt.Component.repaint(int,int,int,int)
java.awt.Component.repaint(long)
java.awt.Component.resize(int,int)
java.awt.Component.resize(java.awt.Dimension)
java.awt.Component.setBounds(int,int,int,int)
java.awt.Component.setBounds(java.awt.Rectangle)
java.awt.Component.setCursor(java.awt.Cursor)
java.awt.Component.setDropTarget(java.awt.dnd.DropTarget)
java.awt.Component.setFocusTraversalKeysEnabled(boolean)
java.awt.Component.setFocusable(boolean)
java.awt.Component.setIgnoreRepaint(boolean)
java.awt.Component.setLocale(java.util.Locale)
java.awt.Component.setLocation(int,int)
java.awt.Component.setLocation(java.awt.Point)
java.awt.Component.setName(java.lang.String)
java.awt.Component.setSize(int,int)
java.awt.Component.setSize(java.awt.Dimension)
java.awt.Component.show()
java.awt.Component.show(boolean)
java.awt.Component.size()
java.awt.Component.toString()
java.awt.Component.transferFocus()
java.awt.Component.transferFocusUpCycle()
java.awt.Container.add(java.awt.Component,java.lang.Object)
java.awt.Container.add(java.awt.Component,java.lang.Object,int)
java.awt.Container.add(java.lang.String,java.awt.Component)
java.awt.Container.addContainerListener(java.awt.event.ContainerListener)
java.awt.Container.addPropertyChangeListener(java.beans.PropertyChangeListener)
java.awt.Container.addPropertyChangeListener(java.lang.String,java.beans.PropertyChangeListener)
java.awt.Container.areFocusTraversalKeysSet(int)
java.awt.Container.countComponents()
java.awt.Container.deliverEvent(java.awt.Event)
java.awt.Container.doLayout()
java.awt.Container.findComponentAt(int,int)
java.awt.Container.findComponentAt(java.awt.Point)
java.awt.Container.getComponent(int)
java.awt.Container.getComponentAt(int,int)
java.awt.Container.getComponentAt(java.awt.Point)
java.awt.Container.getComponentCount()
java.awt.Container.getComponentZOrder(java.awt.Component)
java.awt.Container.getComponents()
java.awt.Container.getContainerListeners()
java.awt.Container.getFocusTraversalKeys(int)
java.awt.Container.getFocusTraversalPolicy()
java.awt.Container.getLayout()
java.awt.Container.getMousePosition(boolean)
java.awt.Container.insets()
java.awt.Container.invalidate()
java.awt.Container.isAncestorOf(java.awt.Component)
java.awt.Container.isFocusCycleRoot()
java.awt.Container.isFocusCycleRoot(java.awt.Container)
java.awt.Container.isFocusTraversalPolicyProvider()
java.awt.Container.isFocusTraversalPolicySet()
java.awt.Container.layout()
java.awt.Container.list(java.io.PrintStream,int)
java.awt.Container.list(java.io.PrintWriter,int)
java.awt.Container.locate(int,int)
java.awt.Container.minimumSize()
java.awt.Container.paintComponents(java.awt.Graphics)
java.awt.Container.preferredSize()
java.awt.Container.printComponents(java.awt.Graphics)
java.awt.Container.removeContainerListener(java.awt.event.ContainerListener)
java.awt.Container.setComponentZOrder(java.awt.Component,int)
java.awt.Container.setFocusCycleRoot(boolean)
java.awt.Container.setFocusTraversalPolicy(java.awt.FocusTraversalPolicy)
java.awt.Container.setFocusTraversalPolicyProvider(boolean)
java.awt.Container.transferFocusBackward()
java.awt.Container.transferFocusDownCycle()
java.awt.Container.validate()
java.lang.Object.equals(java.lang.Object)
java.lang.Object.getClass()
java.lang.Object.hashCode()
java.lang.Object.notify()
java.lang.Object.notifyAll()
java.lang.Object.wait()
java.lang.Object.wait(long)
java.lang.Object.wait(long,int)
javax.swing.AbstractButton.addActionListener(java.awt.event.ActionListener)
javax.swing.AbstractButton.addChangeListener(javax.swing.event.ChangeListener)
javax.swing.AbstractButton.addItemListener(java.awt.event.ItemListener)
javax.swing.AbstractButton.doClick()
javax.swing.AbstractButton.getAction()
javax.swing.AbstractButton.getActionCommand()
javax.swing.AbstractButton.getActionListeners()
javax.swing.AbstractButton.getChangeListeners()
javax.swing.AbstractButton.getDisabledIcon()
javax.swing.AbstractButton.getDisabledSelectedIcon()
javax.swing.AbstractButton.getDisplayedMnemonicIndex()
javax.swing.AbstractButton.getHideActionText()
javax.swing.AbstractButton.getHorizontalAlignment()
javax.swing.AbstractButton.getHorizontalTextPosition()
javax.swing.AbstractButton.getIcon()
javax.swing.AbstractButton.getIconTextGap()
javax.swing.AbstractButton.getItemListeners()
javax.swing.AbstractButton.getLabel()
javax.swing.AbstractButton.getMargin()
javax.swing.AbstractButton.getMnemonic()
javax.swing.AbstractButton.getModel()
javax.swing.AbstractButton.getMultiClickThreshhold()
javax.swing.AbstractButton.getPressedIcon()
javax.swing.AbstractButton.getRolloverIcon()
javax.swing.AbstractButton.getRolloverSelectedIcon()
javax.swing.AbstractButton.getSelectedIcon()
javax.swing.AbstractButton.getSelectedObjects()
javax.swing.AbstractButton.getText()
javax.swing.AbstractButton.getUI()
javax.swing.AbstractButton.getVerticalAlignment()
javax.swing.AbstractButton.getVerticalTextPosition()
javax.swing.AbstractButton.imageUpdate(java.awt.Image,int,int,int,int,int)
javax.swing.AbstractButton.isBorderPainted()
javax.swing.AbstractButton.isContentAreaFilled()
javax.swing.AbstractButton.isFocusPainted()
javax.swing.AbstractButton.isRolloverEnabled()
javax.swing.AbstractButton.removeActionListener(java.awt.event.ActionListener)
javax.swing.AbstractButton.removeChangeListener(javax.swing.event.ChangeListener)
javax.swing.AbstractButton.removeItemListener(java.awt.event.ItemListener)
javax.swing.AbstractButton.removeNotify()
javax.swing.AbstractButton.setAction(javax.swing.Action)
javax.swing.AbstractButton.setActionCommand(java.lang.String)
javax.swing.AbstractButton.setBorderPainted(boolean)
javax.swing.AbstractButton.setContentAreaFilled(boolean)
javax.swing.AbstractButton.setDisabledIcon(javax.swing.Icon)
javax.swing.AbstractButton.setDisabledSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setDisplayedMnemonicIndex(int)
javax.swing.AbstractButton.setFocusPainted(boolean)
javax.swing.AbstractButton.setHideActionText(boolean)
javax.swing.AbstractButton.setHorizontalAlignment(int)
javax.swing.AbstractButton.setHorizontalTextPosition(int)
javax.swing.AbstractButton.setIcon(javax.swing.Icon)
javax.swing.AbstractButton.setIconTextGap(int)
javax.swing.AbstractButton.setLabel(java.lang.String)
javax.swing.AbstractButton.setLayout(java.awt.LayoutManager)
javax.swing.AbstractButton.setMargin(java.awt.Insets)
javax.swing.AbstractButton.setMnemonic(char)
javax.swing.AbstractButton.setMnemonic(int)
javax.swing.AbstractButton.setMultiClickThreshhold(long)
javax.swing.AbstractButton.setPressedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setRolloverEnabled(boolean)
javax.swing.AbstractButton.setRolloverIcon(javax.swing.Icon)
javax.swing.AbstractButton.setRolloverSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setSelectedIcon(javax.swing.Icon)
javax.swing.AbstractButton.setText(java.lang.String)
javax.swing.AbstractButton.setUI(javax.swing.plaf.ButtonUI)
javax.swing.AbstractButton.setVerticalAlignment(int)
javax.swing.AbstractButton.setVerticalTextPosition(int)
javax.swing.JComponent.addAncestorListener(javax.swing.event.AncestorListener)
javax.swing.JComponent.addNotify()
javax.swing.JComponent.addVetoableChangeListener(java.beans.VetoableChangeListener)
javax.swing.JComponent.computeVisibleRect(java.awt.Rectangle)
javax.swing.JComponent.contains(int,int)
javax.swing.JComponent.createToolTip()
javax.swing.JComponent.disable()
javax.swing.JComponent.enable()
javax.swing.JComponent.firePropertyChange(java.lang.String,boolean,boolean)
javax.swing.JComponent.firePropertyChange(java.lang.String,char,char)
javax.swing.JComponent.firePropertyChange(java.lang.String,int,int)
javax.swing.JComponent.getActionForKeyStroke(javax.swing.KeyStroke)
javax.swing.JComponent.getActionMap()
javax.swing.JComponent.getAlignmentX()
javax.swing.JComponent.getAlignmentY()
javax.swing.JComponent.getAncestorListeners()
javax.swing.JComponent.getAutoscrolls()
javax.swing.JComponent.getBaseline(int,int)
javax.swing.JComponent.getBaselineResizeBehavior()
javax.swing.JComponent.getBorder()
javax.swing.JComponent.getBounds(java.awt.Rectangle)
javax.swing.JComponent.getClientProperty(java.lang.Object)
javax.swing.JComponent.getComponentPopupMenu()
javax.swing.JComponent.getConditionForKeyStroke(javax.swing.KeyStroke)
javax.swing.JComponent.getDebugGraphicsOptions()
javax.swing.JComponent.getDefaultLocale()
javax.swing.JComponent.getFontMetrics(java.awt.Font)
javax.swing.JComponent.getGraphics()
javax.swing.JComponent.getHeight()
javax.swing.JComponent.getInheritsPopupMenu()
javax.swing.JComponent.getInputMap()
javax.swing.JComponent.getInputMap(int)
javax.swing.JComponent.getInputVerifier()
javax.swing.JComponent.getInsets()
javax.swing.JComponent.getInsets(java.awt.Insets)
javax.swing.JComponent.getListeners(java.lang.Class)
javax.swing.JComponent.getLocation(java.awt.Point)
javax.swing.JComponent.getMaximumSize()
javax.swing.JComponent.getMinimumSize()
javax.swing.JComponent.getNextFocusableComponent()
javax.swing.JComponent.getPopupLocation(java.awt.event.MouseEvent)
javax.swing.JComponent.getPreferredSize()
javax.swing.JComponent.getRegisteredKeyStrokes()
javax.swing.JComponent.getRootPane()
javax.swing.JComponent.getSize(java.awt.Dimension)
javax.swing.JComponent.getToolTipLocation(java.awt.event.MouseEvent)
javax.swing.JComponent.getToolTipText()
javax.swing.JComponent.getToolTipText(java.awt.event.MouseEvent)
javax.swing.JComponent.getTopLevelAncestor()
javax.swing.JComponent.getTransferHandler()
javax.swing.JComponent.getVerifyInputWhenFocusTarget()
javax.swing.JComponent.getVetoableChangeListeners()
javax.swing.JComponent.getVisibleRect()
javax.swing.JComponent.getWidth()
javax.swing.JComponent.getX()
javax.swing.JComponent.getY()
javax.swing.JComponent.grabFocus()
javax.swing.JComponent.isDoubleBuffered()
javax.swing.JComponent.isLightweightComponent(java.awt.Component)
javax.swing.JComponent.isManagingFocus()
javax.swing.JComponent.isOpaque()
javax.swing.JComponent.isOptimizedDrawingEnabled()
javax.swing.JComponent.isPaintingForPrint()
javax.swing.JComponent.isPaintingTile()
javax.swing.JComponent.isRequestFocusEnabled()
javax.swing.JComponent.isValidateRoot()
javax.swing.JComponent.paint(java.awt.Graphics)
javax.swing.JComponent.paintImmediately(int,int,int,int)
javax.swing.JComponent.paintImmediately(java.awt.Rectangle)
javax.swing.JComponent.print(java.awt.Graphics)
javax.swing.JComponent.printAll(java.awt.Graphics)
javax.swing.JComponent.putClientProperty(java.lang.Object,java.lang.Object)
javax.swing.JComponent.registerKeyboardAction(java.awt.event.ActionListener,java.lang.String,javax.swing.KeyStroke,int)
javax.swing.JComponent.registerKeyboardAction(java.awt.event.ActionListener,javax.swing.KeyStroke,int)
javax.swing.JComponent.removeAncestorListener(javax.swing.event.AncestorListener)
javax.swing.JComponent.removeVetoableChangeListener(java.beans.VetoableChangeListener)
javax.swing.JComponent.repaint(java.awt.Rectangle)
javax.swing.JComponent.repaint(long,int,int,int,int)
javax.swing.JComponent.requestDefaultFocus()
javax.swing.JComponent.requestFocus()
javax.swing.JComponent.requestFocus(boolean)
javax.swing.JComponent.requestFocusInWindow()
javax.swing.JComponent.resetKeyboardActions()
javax.swing.JComponent.reshape(int,int,int,int)
javax.swing.JComponent.revalidate()
javax.swing.JComponent.scrollRectToVisible(java.awt.Rectangle)
javax.swing.JComponent.setActionMap(javax.swing.ActionMap)
javax.swing.JComponent.setAlignmentX(float)
javax.swing.JComponent.setAlignmentY(float)
javax.swing.JComponent.setAutoscrolls(boolean)
javax.swing.JComponent.setBackground(java.awt.Color)
javax.swing.JComponent.setBorder(javax.swing.border.Border)
javax.swing.JComponent.setComponentPopupMenu(javax.swing.JPopupMenu)
javax.swing.JComponent.setDebugGraphicsOptions(int)
javax.swing.JComponent.setDefaultLocale(java.util.Locale)
javax.swing.JComponent.setDoubleBuffered(boolean)
javax.swing.JComponent.setFocusTraversalKeys(int,java.util.Set)
javax.swing.JComponent.setFont(java.awt.Font)
javax.swing.JComponent.setForeground(java.awt.Color)
javax.swing.JComponent.setInheritsPopupMenu(boolean)
javax.swing.JComponent.setInputMap(int,javax.swing.InputMap)
javax.swing.JComponent.setInputVerifier(javax.swing.InputVerifier)
javax.swing.JComponent.setMaximumSize(java.awt.Dimension)
javax.swing.JComponent.setMinimumSize(java.awt.Dimension)
javax.swing.JComponent.setNextFocusableComponent(java.awt.Component)
javax.swing.JComponent.setOpaque(boolean)
javax.swing.JComponent.setPreferredSize(java.awt.Dimension)
javax.swing.JComponent.setRequestFocusEnabled(boolean)
javax.swing.JComponent.setToolTipText(java.lang.String)
javax.swing.JComponent.setTransferHandler(javax.swing.TransferHandler)
javax.swing.JComponent.setVerifyInputWhenFocusTarget(boolean)
javax.swing.JComponent.setVisible(boolean)
javax.swing.JComponent.unregisterKeyboardAction(javax.swing.KeyStroke)
javax.swing.JComponent.update(java.awt.Graphics)
javax.swing.JMenu.add(java.awt.Component)
javax.swing.JMenu.add(java.awt.Component,int)
javax.swing.JMenu.add(java.lang.String)
javax.swing.JMenu.add(javax.swing.Action)
javax.swing.JMenu.add(javax.swing.JMenuItem)
javax.swing.JMenu.addMenuListener(javax.swing.event.MenuListener)
javax.swing.JMenu.addSeparator()
javax.swing.JMenu.applyComponentOrientation(java.awt.ComponentOrientation)
javax.swing.JMenu.doClick(int)
javax.swing.JMenu.getAccessibleContext()
javax.swing.JMenu.getComponent()
javax.swing.JMenu.getDelay()
javax.swing.JMenu.getItem(int)
javax.swing.JMenu.getItemCount()
javax.swing.JMenu.getMenuComponent(int)
javax.swing.JMenu.getMenuComponentCount()
javax.swing.JMenu.getMenuComponents()
javax.swing.JMenu.getMenuListeners()
javax.swing.JMenu.getPopupMenu()
javax.swing.JMenu.getSubElements()
javax.swing.JMenu.getUIClassID()
javax.swing.JMenu.insert(java.lang.String,int)
javax.swing.JMenu.insert(javax.swing.Action,int)
javax.swing.JMenu.insert(javax.swing.JMenuItem,int)
javax.swing.JMenu.insertSeparator(int)
javax.swing.JMenu.isMenuComponent(java.awt.Component)
javax.swing.JMenu.isPopupMenuVisible()
javax.swing.JMenu.isSelected()
javax.swing.JMenu.isTearOff()
javax.swing.JMenu.isTopLevelMenu()
javax.swing.JMenu.menuSelectionChanged(boolean)
javax.swing.JMenu.remove(int)
javax.swing.JMenu.remove(java.awt.Component)
javax.swing.JMenu.remove(javax.swing.JMenuItem)
javax.swing.JMenu.removeAll()
javax.swing.JMenu.removeMenuListener(javax.swing.event.MenuListener)
javax.swing.JMenu.setAccelerator(javax.swing.KeyStroke)
javax.swing.JMenu.setComponentOrientation(java.awt.ComponentOrientation)
javax.swing.JMenu.setDelay(int)
javax.swing.JMenu.setMenuLocation(int,int)
javax.swing.JMenu.setModel(javax.swing.ButtonModel)
javax.swing.JMenu.setPopupMenuVisible(boolean)
javax.swing.JMenu.setSelected(boolean)
javax.swing.JMenu.updateUI()
javax.swing.JMenuItem.addMenuDragMouseListener(javax.swing.event.MenuDragMouseListener)
javax.swing.JMenuItem.addMenuKeyListener(javax.swing.event.MenuKeyListener)
javax.swing.JMenuItem.getAccelerator()
javax.swing.JMenuItem.getMenuDragMouseListeners()
javax.swing.JMenuItem.getMenuKeyListeners()
javax.swing.JMenuItem.isArmed()
javax.swing.JMenuItem.processKeyEvent(java.awt.event.KeyEvent,javax.swing.MenuElement[],javax.swing.MenuSelectionManager)
javax.swing.JMenuItem.processMenuDragMouseEvent(javax.swing.event.MenuDragMouseEvent)
javax.swing.JMenuItem.processMenuKeyEvent(javax.swing.event.MenuKeyEvent)
javax.swing.JMenuItem.processMouseEvent(java.awt.event.MouseEvent,javax.swing.MenuElement[],javax.swing.MenuSelectionManager)
javax.swing.JMenuItem.removeMenuDragMouseListener(javax.swing.event.MenuDragMouseListener)
javax.swing.JMenuItem.removeMenuKeyListener(javax.swing.event.MenuKeyListener)
javax.swing.JMenuItem.setArmed(boolean)
javax.swing.JMenuItem.setEnabled(boolean)
javax.swing.JMenuItem.setUI(javax.swing.plaf.MenuItemUI)
How This List Was Generated
I ran the following lines of JavaScript in my Firebug console:
jmenu = new Packages.javax.swing.JMenu( );
methods = jmenu.getClass( ).getMethods( );
r = /j[^( ]+\([^)]*\)/; // match just the method
for (var i = 0,
jsArray=[],
name = ""; i < methods.length; i++ ) {
name = methods[ i ].toString( );
jsArray.push( name.match( r )[ 0 ] );
}
markup = jsArray.sort( ).join( "<br/>" );
document.body.innerHTML = markup;
The key thing to understand is that you can call Java from JavaScript, in Firefox, using the Packages syntax (as shown above). Security restrictions will keep you from doing anything too interesting with scripted Java, but it's noteworthy that you can at least instantiate Java objects, including Swing objects, this way.
BTW, if you find a Java class that has more than 433 methods (clue: I do know of one more Swing class that has > 433 methods), let me know what it is. I'll credit you here.
Subscribe to:
Posts (Atom)