Julian Wraith (@julesdw) recently challenged CMS pundits to pen a blog post on the future of Content Management. He didn't say whether there was a T-shirt involved. But I decided to take a quick stab at it. The detailed post is at CMS Watch. I'll add a few thoughts here too.
My main observation is that metadata management is really what we mean by content management today. Content is the payload; it's what gets consumed. Metadata determines how the payload is managed. It's what makes the content manageable.
As I point out in the CMS Watch blog post, content, today, is not what we used to think of as content ten or fifteen years ago. Content used to mean document. Then for a while it meant HTML, or the artifacts destined to make up a web page. Now it means whatever it means. Content can be anything. Which is good, because now we don't have to argue over what content is.
One thing almost everyone I talk to agrees on is that content is becoming rich and unruly. It is becoming less structured, more diverse as to composition and mimetype, and ultimately less manageable. Twenty years ago you didn't have such a thing as a PDF file with embedded Flash. Now you do. Ten years ago the Word (.doc) format contained no XML. Now it does. Composite files are everywhere. Ephemeral (consume-once) content is everywhere. Audio and video files are everywhere. That's a lot to manage.
I've been telling anyone who'll listen that if you want to manage content, or design software systems that do, you have to think of content entirely abstractly. Content can be anything. For management purposes, you shouldn't have to know in advance what the content is; your system should be capable of managing any kind of content. It should be able to let you find content, search content, version it, access-control it, workflow it, etc., without knowing or caring that the content is structured, unstructured, flat, hierarchical, text, binary, animal, vegetable, or mineral.
Since content can be anything, it has to be managed through descriptors (metadata). This is an extremely important concept. Ten years ago, you could code the detailed knowledge of how to handle HTML and other web formats directly into a CMS. Today that would be foolish. Even in a Web CMS, the core code should know nothing about HTML. Detailed knowledge about a content type exists in applications and modules living several abstraction layers above the core code. The system itself needs to be mimetype-agnostic.
A file's metadata is the shim between the core CMS and the applications that consume the content. It's the content's interface to the outside world. The metadata describing a piece of content is analogous to the WSDL describing a Web Service. It says "Here's where am I, here's what you can do with me, here's what you need to know about accessing me."
Not to put too fine a point on it, but: Everything you need to know in order to manage a piece of content is, or should be, in its metadata.
In a nutshell: The Future of Content Management is about metadata. But also, the Present of Content Management is about metadata. The future, make no mistake, is here already.6f82f1d2683dc522545efe863e5d2b73
Monday, August 31, 2009
Sunday, August 30, 2009
Worse is better
I was reading yesterday about Richard P. Gabriel's classic worse-is-better theory, which wraps a lot of related concepts, such as less is more, good enough is good enough, KISS, and YAGNI. The key intuition is that the more you try to perfect something by adding to it, the less perfect it gets -- so don't try to perfect it. Leave it imperfect, it'll be better that way. Worse is better.
Alas, worse-is-better goes against more entrenched philosophies like "correctness before efficiency" and "completeness over simplicity."
On a business level, it goes against the philosophy of give-the-customer-every-damn-feature-he-wants. It says let's leave a large number of ultimately unimportant features out, and concentrate on making the rest do what it's supposed to do.
A prototype or proof-of-concept that slam-dunks the desired functionality, but sucks at the code level because classes aren't cleanly factored, is an example of worse-is-better. Chances are, when the POC is later discarded, then reimplemented "correctly" by a team of GoF acolytes, it will morph into an overfactored, underperforming pig with unexplainable memory leaks and a hard-to-describe odor. (But hey, it'll scale.)
Is worse always better? Of course not. Better is, by and large, better. Just not in the software world, where "better" tends to take on unexpected meanings.
Alas, worse-is-better goes against more entrenched philosophies like "correctness before efficiency" and "completeness over simplicity."
On a business level, it goes against the philosophy of give-the-customer-every-damn-feature-he-wants. It says let's leave a large number of ultimately unimportant features out, and concentrate on making the rest do what it's supposed to do.
A prototype or proof-of-concept that slam-dunks the desired functionality, but sucks at the code level because classes aren't cleanly factored, is an example of worse-is-better. Chances are, when the POC is later discarded, then reimplemented "correctly" by a team of GoF acolytes, it will morph into an overfactored, underperforming pig with unexplainable memory leaks and a hard-to-describe odor. (But hey, it'll scale.)
Is worse always better? Of course not. Better is, by and large, better. Just not in the software world, where "better" tends to take on unexpected meanings.
Saturday, August 29, 2009
The UNIX Way
Maybe because I analyze and write about enterprise software for a living (or maybe simply because I'm a Vista user), I tend to spend a lot of time thinking about the messiness and sloth of software systems, and what, if anything, can be done about it. Short of returning to Intel 8086 and Motorola MC68000 chipsets, I'm not sure anything can be done at this point. But that doesn't mean we stop trying.
One source of inspiration is the UNIX philosophy. In 1994 Mike Gancarz (a member of the team that designed the X Window System) articulated "The UNIX Philosophy" as a list of nine principles, drawing on his own experiences with UNIX as well as those of friends and colleagues in the UNIX community. Gancarz summed up the nine principles this way:
- Small is beautiful.
- Make each program do one thing well.
- Build a prototype as soon as possible.
- Choose portability over efficiency.
- Store data in flat text files.
- Use software leverage to your advantage.
- Use shell scripts to increase leverage and portability.
- Avoid captive user interfaces.
- Make every program a filter
Obviously these principles, as stated, are not directly transferrable to the world of enterprise software development. But they speak to a certain aesthetic that can be (and needs to be) emulated, I think, if the enterprise world is ever going to get past the point of "not good enough is good enough."
Friday, August 28, 2009
Is PHP staging a comeback?

PHP never really went away, of course. But it does appear to be gathering renewed momentum of late. Compare the trendline for ColdFusion.
Graph courtesy of Indeed.com.
Thursday, August 27, 2009
Calling WolframAlpha what it really is
If you look at WolframAlpha's logo, it says "Computational Knowledge Engine." That's accurate, maybe, but it's jargonly, doesn't exactly roll off the tongue, and as a promotional aid? Fail Bigtime. Non-technical users will be scared off by such talk.
So I sent the WA team a note:
Anxious to see what they say. I'd love to see the word "oracle" reenter the English language with its original meaning, before it was appropriated by Larry Ellison.
So I sent the WA team a note:
"Computational Knowledge Engine" is a mouthful and will scare off non-techie non-geek users. To you and me it sounds perfectly acceptable, but really it's not helping WA get users or press; it's off-putting. My suggestion is to build a moniker around the simple word "oracle." Techies will "get" the traditional technical meaning of that term, and non-geeks will at least get that WA isn't really a search engine.
Anxious to see what they say. I'd love to see the word "oracle" reenter the English language with its original meaning, before it was appropriated by Larry Ellison.
Wednesday, August 26, 2009
How to make any web page inline-editable
It's really not such a big trick to enable in-page editing of Web pages. The major browsers support a property called designMode on the document object. If you set its value to "on," you've got an editable page.
If you want to see quick proof of this, copy and paste the following line into your address bar right now and hit Enter:
javascript:document.designMode="on";void(0);
You'll notice that this page is now editable (unless you're using Internet Explorer, in which case all bets are off). Drag various graphic elements around. Edit the text. Play around a while. (I'll wait.) See what I mean?
Internet Explorer has something similar called contentEditable (which you set to true or false). But the security provisions of IE are so convoluted these days, I'm not even sure which versions of IE support contentEditable or designMode any more.
In any case, I wanted to put a menu command on the Firefox menu system to enable inline editing so that I don't have to resort to copying that line of JavaScript into Firefox's address bar. I also wanted to make it easy to turn inline editing off. (This can be surprisingly hard to do, because once you enable Design Mode in Firefox, you can no longer run scripts within the window's scope. Hence you can't use JavaScript to set designMode to "off.")
Greasemonkey makes all this a cinch. There's a registerMenuCommand method that lets you put menu commands under the Greasemonkey submenus in Firefox's Tools menu, which is incredibly nice because it lets you load a Greasemonkey script any time you want (just by using the menu command) rather than always at page-load time.
But what about turning Design Mode off after switching it on? Well, again, this is where Greasemonkey shines. If you create a DOM node that's visible (e.g., a text span) and attach (let's say) an onclick listener to it, you can turn off Design Mode in the listener (when the user clicks the text), because the listener runs in Greasemonkey's scope, not the window object's.
The following Greasemonkey script puts a command, "Enable Design Mode," under Tools > Greasemonkey > User Script Commands. If you invoke the command, a text span containing the words "DESIGN MODE" (black letters on a red background) will appear in the upper left corner of the current page. The page will be editable at that point. To get out of Design Mode, you simply click anywhere on the words DESIGN MODE.
You might be asking "What good is it to edit a browser page if the edits aren't permanent?" There are several possible answers. I sometimes use Design Mode in conjunction with Cut and Paste to aggregate several items (from several pages) onto a single page that I can save to disk for later use. (As it turns out, I also wrote a Sling app that lets me save the page to a Jackrabbit repository. A story for another day, perhaps.)
Just while writing this blog, I used Design Mode to get the above code to look the way I wanted. Originally, I used the code beautifier at Pluszone to take my ugly raw-text source code and make it colorful and properly indented. But the code beautifier left some indents not quite right. I went into Design Mode and manually fixed the indents right in the rendered page. Then I grabbed the HTML source for the page and pasted it into the Blogger editor in order to produce what you see above.
Sometimes I use Design Mode to doctor a page before taking a screen shot. Also, I occasionally use it to cut and paste photos from various unrelated pages to a single aggregation page. The neat thing about doing that is that if the photos in question have underlying hypertext links, the links get copied too (and still work after you exit Design Mode on the target page); you can still click the copied photos.
Magic? Hardly. But that's the point. Being able to do in-page editing is not such a big deal. The real challenge is in doing it well. For that, of course, you need more than a few lines of JavaScript.
If you want to see quick proof of this, copy and paste the following line into your address bar right now and hit Enter:
javascript:document.designMode="on";void(0);
You'll notice that this page is now editable (unless you're using Internet Explorer, in which case all bets are off). Drag various graphic elements around. Edit the text. Play around a while. (I'll wait.) See what I mean?
Internet Explorer has something similar called contentEditable (which you set to true or false). But the security provisions of IE are so convoluted these days, I'm not even sure which versions of IE support contentEditable or designMode any more.
In any case, I wanted to put a menu command on the Firefox menu system to enable inline editing so that I don't have to resort to copying that line of JavaScript into Firefox's address bar. I also wanted to make it easy to turn inline editing off. (This can be surprisingly hard to do, because once you enable Design Mode in Firefox, you can no longer run scripts within the window's scope. Hence you can't use JavaScript to set designMode to "off.")
Greasemonkey makes all this a cinch. There's a registerMenuCommand method that lets you put menu commands under the Greasemonkey submenus in Firefox's Tools menu, which is incredibly nice because it lets you load a Greasemonkey script any time you want (just by using the menu command) rather than always at page-load time.
But what about turning Design Mode off after switching it on? Well, again, this is where Greasemonkey shines. If you create a DOM node that's visible (e.g., a text span) and attach (let's say) an onclick listener to it, you can turn off Design Mode in the listener (when the user clicks the text), because the listener runs in Greasemonkey's scope, not the window object's.
The following Greasemonkey script puts a command, "Enable Design Mode," under Tools > Greasemonkey > User Script Commands. If you invoke the command, a text span containing the words "DESIGN MODE" (black letters on a red background) will appear in the upper left corner of the current page. The page will be editable at that point. To get out of Design Mode, you simply click anywhere on the words DESIGN MODE.
You might be asking "What good is it to edit a browser page if the edits aren't permanent?" There are several possible answers. I sometimes use Design Mode in conjunction with Cut and Paste to aggregate several items (from several pages) onto a single page that I can save to disk for later use. (As it turns out, I also wrote a Sling app that lets me save the page to a Jackrabbit repository. A story for another day, perhaps.)
Just while writing this blog, I used Design Mode to get the above code to look the way I wanted. Originally, I used the code beautifier at Pluszone to take my ugly raw-text source code and make it colorful and properly indented. But the code beautifier left some indents not quite right. I went into Design Mode and manually fixed the indents right in the rendered page. Then I grabbed the HTML source for the page and pasted it into the Blogger editor in order to produce what you see above.
Sometimes I use Design Mode to doctor a page before taking a screen shot. Also, I occasionally use it to cut and paste photos from various unrelated pages to a single aggregation page. The neat thing about doing that is that if the photos in question have underlying hypertext links, the links get copied too (and still work after you exit Design Mode on the target page); you can still click the copied photos.
Magic? Hardly. But that's the point. Being able to do in-page editing is not such a big deal. The real challenge is in doing it well. For that, of course, you need more than a few lines of JavaScript.
Tuesday, August 25, 2009
Using Mozilla Jetpack to save tab ensembles
I haven't played with Jetpack all that much since I last wrote about it. I did write a script that collects all the URLs and page titles of all open Firefox tabs and displays them in a table, so that I can Save the table and be able to return to a given tab configuration any time I want. Right now I just save the page to disk manually. But a proper implementation would use Jetpack's persistence API (and a nice UI) to make the process easier.
But that got me thinking. Why is it Firefox doesn't already offer this capability? First let's define what we're talking about. I'm thinking there should be a special name (an agreed-upon technical term) for a particular collection of open tabs in a browser. The name I propose is simply ensemble. At the moment, I have 4 tabs open in Firefox: The Blogger editing window, Twitter's Search page, the Mozilla Jetpack contest page, and Google. I should be able to Save this configuration off as a named collection; let's call it "The tabs for that Jetpack followup blog." That's an ensemble.
Tomorrow at this time I might very well have 20 tabs open, including cmswire.com, several CMS Watch pages, Central Desktop (which we use a lot at CMS Watch), Files Anywhere (ditto), Google Calendar, Gmail, and who knows what else. At the moment, in my day job, I'm doing a bit of writing about Oracle Universal Content Management, and yesterday I had six different PDFs (UCM documentation) open in Firefox tabs, plus all the usual nonsense. I'd like to be able to capture all of those tabs as one named collection, one ensemble, that I can passivate (and reanimate later, at my leisure).
Am I missing something? Can Firefox already do this? Yes yes, I realize that I can quit Firefox and have my current tab configuration saved for the next time I start Firefox, but that's not at all the same as saving off different named, tagged ensembles (saving them at any time, not just quitting time) that I can choose to reinstate later.
I know there are services out on the Web where I can dump collections of bookmarks. That's not what I want. I want to do everything from within Firefox.
At any rate, the code I'm using right now to get the titles and URLs of all open tabs and display them in a table onscreen looks like this:
It's ugly code and I'm sure it can be improved in a hundred different ways, but hey, it's just a proof of concept, so if it blows up no one loses their hands.
I wrote the shorten( ) macro, btw, before I realized Jetpack had an ellipsify() method.
In conjunction with the script, I use a dummy HTML page called tabs.htm that just contains a single <div> in the body. That's where I attach the table of results.
Nothing special, I know.
How about you? Have you written any Jetpack code lately? (Are you entering the contest?) If so, please tell me about it. I'd like to know what you're doing and what your impressions are of Jetpack so far. My overall impression of Jetpack remains positive. I'm anxious to see where it'll take us next.
But that got me thinking. Why is it Firefox doesn't already offer this capability? First let's define what we're talking about. I'm thinking there should be a special name (an agreed-upon technical term) for a particular collection of open tabs in a browser. The name I propose is simply ensemble. At the moment, I have 4 tabs open in Firefox: The Blogger editing window, Twitter's Search page, the Mozilla Jetpack contest page, and Google. I should be able to Save this configuration off as a named collection; let's call it "The tabs for that Jetpack followup blog." That's an ensemble.
Tomorrow at this time I might very well have 20 tabs open, including cmswire.com, several CMS Watch pages, Central Desktop (which we use a lot at CMS Watch), Files Anywhere (ditto), Google Calendar, Gmail, and who knows what else. At the moment, in my day job, I'm doing a bit of writing about Oracle Universal Content Management, and yesterday I had six different PDFs (UCM documentation) open in Firefox tabs, plus all the usual nonsense. I'd like to be able to capture all of those tabs as one named collection, one ensemble, that I can passivate (and reanimate later, at my leisure).
Am I missing something? Can Firefox already do this? Yes yes, I realize that I can quit Firefox and have my current tab configuration saved for the next time I start Firefox, but that's not at all the same as saving off different named, tagged ensembles (saving them at any time, not just quitting time) that I can choose to reinstate later.
I know there are services out on the Web where I can dump collections of bookmarks. That's not what I want. I want to do everything from within Firefox.
At any rate, the code I'm using right now to get the titles and URLs of all open tabs and display them in a table onscreen looks like this:
jetpack.tabs.onReady( renderTabList );
function renderTabList( doc ) {
var TRIGGER_PAGE = "tabs.htm";
var tabs = jetpack.tabs;
var currentUrl = doc.location.href;
if ( currentUrl.indexOf( TRIGGER_PAGE ) == -1 )
return; // only fire when tabs.htm loads
var markup = "<table>";
for ( var i = 0; i < tabs.length; i++ ) {
var title =
$( tabs[ i ].contentDocument ).find( "title" ).text( );
var url = tabs[ i ].url;
if ( url.indexOf( TRIGGER_PAGE ) != -1 ||
url.indexOf( "about:") != -1 )
continue; // don't include ourselves
function shorten( str, limit )
str.length > limit ?
str.substring( 0, limit ) + "... " : str;
title = shorten( title, "... " );
var visibleUrl = shorten( url, "... " );
markup += "<tr>";
markup += "<td>" + title + "</td>";
markup += "<td>" + visibleUrl.link( url ) + "</td>";
markup += "</tr>";
}
markup += "</table>";
$( doc ).find( 'div' ).html( markup );
}
It's ugly code and I'm sure it can be improved in a hundred different ways, but hey, it's just a proof of concept, so if it blows up no one loses their hands.
I wrote the shorten( ) macro, btw, before I realized Jetpack had an ellipsify() method.
In conjunction with the script, I use a dummy HTML page called tabs.htm that just contains a single <div> in the body. That's where I attach the table of results.
Nothing special, I know.
How about you? Have you written any Jetpack code lately? (Are you entering the contest?) If so, please tell me about it. I'd like to know what you're doing and what your impressions are of Jetpack so far. My overall impression of Jetpack remains positive. I'm anxious to see where it'll take us next.
Monday, August 24, 2009
Emotions and Usability
Lately I've been thinking a lot about the subtle interplay between emotions, usability, and the factors common to good design. And what I've decided is, the fitness-to-purpose proponents have got it all wrong. Usability isn't about fitness to purpose, unless you're designing toothpicks. For anything more sophisticated than a toothpick, usability must take into account the user's total body response to the product.
Total body response means how you perceive the product or technology in question using all of your senses and all of your faculties, on all levels. Usability has an unavoidable aesthetic component.
Aesthetic can refer to a dimension of perceived beauty, but I'm thinking of a more general meaning. Kant maintains the ancient Greek usage, in which anything relating to sensory perception may be called aesthetic. This is closer to the mark. It treats aesthetic perception as part of, indeed integral to, cognition.
All makes and models of car have 4 wheels and will get me to Walmart and back. They all meet the fitness-to-purpose test. But each has a different personality; and (maybe you've noticed?) we interact with our vehicles at the level of personality. We have an emotional response to cars. (Some of us do, anyway.) It's a total body response.
Frank Spillers points out that Vygotsky and LeDoux (among others) believed that the separation of affect from cognition constituted a major weakness in the field of cognitive science and the study of psychology generally.
Usability experts, likewise, are starting to come around to the point of view that cognition is not only informed by affect but steered by it.
In 2007, three Penn State University researchers found that users judged the relevancy of search results to be better with Yahoo! and Google than with other search engines, even though, in the study, all search results were identical. Question: Is this an example of fitness to purpose, or is something much deeper going on here?
Emotional design is founded not in theory but in reality. Studies have shown that an interface that's perceived as highly usable (e.g., iPhone) will typically also be perceived as aesthetically pleasing. Conversely, things that are pleasing are often judged to work well.
We shouldn't be surprised by this. We should take a hint from it -- and modify our practices around usability accordingly. Not for the sake of doing so, but for business value. As Frank Spillers says:
For more on this subject, by the way, I highly recommend Anderson's slideshow, Eye Candy is a Critical Business Requirement.
From now on, when you hear the term "eye candy," don't think empty calories. Think substance. Ask yourself whether the product you're selling (or designing) can dilute pupils. If it's not a pupil-popper? The odds are good that it doesn't measure up.
Total body response means how you perceive the product or technology in question using all of your senses and all of your faculties, on all levels. Usability has an unavoidable aesthetic component.
Aesthetic can refer to a dimension of perceived beauty, but I'm thinking of a more general meaning. Kant maintains the ancient Greek usage, in which anything relating to sensory perception may be called aesthetic. This is closer to the mark. It treats aesthetic perception as part of, indeed integral to, cognition.
All makes and models of car have 4 wheels and will get me to Walmart and back. They all meet the fitness-to-purpose test. But each has a different personality; and (maybe you've noticed?) we interact with our vehicles at the level of personality. We have an emotional response to cars. (Some of us do, anyway.) It's a total body response.
Frank Spillers points out that Vygotsky and LeDoux (among others) believed that the separation of affect from cognition constituted a major weakness in the field of cognitive science and the study of psychology generally.
Usability experts, likewise, are starting to come around to the point of view that cognition is not only informed by affect but steered by it.
In 2007, three Penn State University researchers found that users judged the relevancy of search results to be better with Yahoo! and Google than with other search engines, even though, in the study, all search results were identical. Question: Is this an example of fitness to purpose, or is something much deeper going on here?
Emotional design is founded not in theory but in reality. Studies have shown that an interface that's perceived as highly usable (e.g., iPhone) will typically also be perceived as aesthetically pleasing. Conversely, things that are pleasing are often judged to work well.
We shouldn't be surprised by this. We should take a hint from it -- and modify our practices around usability accordingly. Not for the sake of doing so, but for business value. As Frank Spillers says:
Stephen Anderson puts it this way: "Pretty is not decoration. Pretty is function."Emotion is one of the strongest differentiators in user experience, namely because it triggers unconscious responses to a product, website, environment, or interface. Our feelings strongly influence our perceptions and often frame how we think about or refer to our experiences at a later date.
When we think about emotion design and usability, we typically think of it as "keeping the user happy". This includes designing to minimize the common emotions related to poor usability such as frustration, annoyance, anger and confusion.
For more on this subject, by the way, I highly recommend Anderson's slideshow, Eye Candy is a Critical Business Requirement.
From now on, when you hear the term "eye candy," don't think empty calories. Think substance. Ask yourself whether the product you're selling (or designing) can dilute pupils. If it's not a pupil-popper? The odds are good that it doesn't measure up.
Sunday, August 23, 2009
Mozilla Jetpack Update
The Mozilla Labs crew continues to put a surprising amount of muscle behind Jetpack. I note with interest that Mozilla is looking to hire an engineer (http://3.ly/ic3) and a PM (http://3.ly/4Uf) specifically to work on Jetpack. The fact that Mozilla is creating two new positions (in this economy, especially) tells me they're committed to the Jetpack project. It's not just a (forgive me) "fly by night" affair.
In addition, I think it's interesting that Mozilla Labs recently announced a Jetpack Liftoff code contest, which ends October 15, 2009. The grand prize winner will receive an ASUS Eee PC 1000HE Black Netbook computer (ARV: $399). The runner-up prize winner will receive stickers and a t-shirt (ARV: $100).
Version 0.5 of Jetpack is set to hit tomorrow night, with a Labs blog about it the following morning.
More exciting to me personally is the fact that the API has expanded significantly. I won't run through any of the new methods here (even though I know you're dying to hear about them in excruciating detail right this minute), but you can sneak a peek at the doc here.
It will be interesting to see what comes out of the contest. Jetpack is at a pivotal point in its career right now. It badly needs a Killer App. It's kill or be killed, in the browser world, and frankly the world doesn't want for APIs at this point. So it behooves MozLabs to slam-dunk this one. If it were me, I would have upped the ante and made the grand prize for the code contest a little grander: a real jetpack. It doesn't say much to give away a $400 netbook, IMHO. (At the very least, give away a fully tricked-out Powerbook. And maybe a claw hammer signed by IceT.)
But then, what do I know about running a contest? I barely know which end of the claw hammer to pound the keyboard with.
In addition, I think it's interesting that Mozilla Labs recently announced a Jetpack Liftoff code contest, which ends October 15, 2009. The grand prize winner will receive an ASUS Eee PC 1000HE Black Netbook computer (ARV: $399). The runner-up prize winner will receive stickers and a t-shirt (ARV: $100).
Version 0.5 of Jetpack is set to hit tomorrow night, with a Labs blog about it the following morning.
More exciting to me personally is the fact that the API has expanded significantly. I won't run through any of the new methods here (even though I know you're dying to hear about them in excruciating detail right this minute), but you can sneak a peek at the doc here.
It will be interesting to see what comes out of the contest. Jetpack is at a pivotal point in its career right now. It badly needs a Killer App. It's kill or be killed, in the browser world, and frankly the world doesn't want for APIs at this point. So it behooves MozLabs to slam-dunk this one. If it were me, I would have upped the ante and made the grand prize for the code contest a little grander: a real jetpack. It doesn't say much to give away a $400 netbook, IMHO. (At the very least, give away a fully tricked-out Powerbook. And maybe a claw hammer signed by IceT.)
But then, what do I know about running a contest? I barely know which end of the claw hammer to pound the keyboard with.
Saturday, August 22, 2009
IceT disassembles a Powerbook
When I first started to watch this video, I was filled with a sense of revulsion and apprehension. By the end of it, I had tears of laughter streaming down my face. That may say more about me than about the video, but so be it. This is performance art at its best. What can I say? I laughed, I cried, it became a part of me.
Friday, August 21, 2009
Back from Hiatus
Yes, I'm back from Hiatus, which is a small island nestled between Anomie and Ennui in the southern Doldrums. Actually, I decided to take a break from JavaScript hackery and other forms of bitbanging for a while in order to do a little painting (linseed-oil therapy).
But I'm back now, so I'll be posting updates here more regularly as the summer winds down. Which it's doing all too quickly, I fear.
But I'm back now, so I'll be posting updates here more regularly as the summer winds down. Which it's doing all too quickly, I fear.
Saturday, August 01, 2009
Learning to Love Jetpack, Part 2
Mozilla Jetpack is an interesting beast, sitting (as it does) at the crossroads of Spidermonkey and XPCOM. It brings JavaScript programmers within a stone's throw of the imressive XPCOM API with its 1450 interfaces and 890 components, plus it unlocks a world of cross-platform AJAX capabilities and local data persistence. Mind you, Jetpack does not actually hand you the keys to the entire XPCOM universe; that may come later. Right now you just get access to certain wrapped objects. But there's more than enough power under the hood to give Greasemonkey a run for the money.
If you're already familiar with Greasemonkey, you'll grok the basics of Jetpack instantly. A fundamental pattern is firing a script when a page loads in Firefox (except, you have to start thinking in terms of "tabs," not pages). So for example,
The "We're not in Kansas any more, Toto" feeling starts to hit you when you realize that your script can walk the entire list of open tabs and vulture any or all DOMs and/or window objects, for all frames in all tabs; something you can't do in Greasemonkey, since GM is scoped to the current window.
Also, you have access to jQuery. So if you want to see how many links a page contains, you can do:
Developing for Jetpack takes a little getting used to. First, of course, you have to install the Jetpack extension. The direct download link, at the moment, is here, but it could go stale by the time you read this. If so, go straight to https://jetpack.mozillalabs.com/.
To get to the development environment, you have to type "about:jetpack" in Firefox's address bar and hit Enter. When you do that, you'll see something like this:
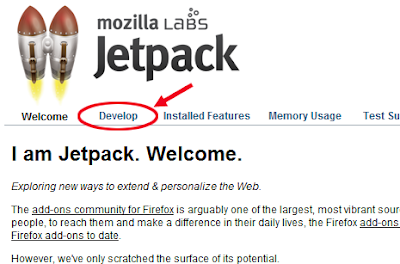
There are several links across the top of the page (Welcome, Develop, etc.). It's not obvious that they are links, because they are not in the usual shade of blue and aren't underlined. Nevertheless, to do any actual code development in the embedded Bespin editor, you have to click the word "Develop" (which I've circled in red above). This brings up a page where, if you scroll down, you'll see a black-background text editor console.
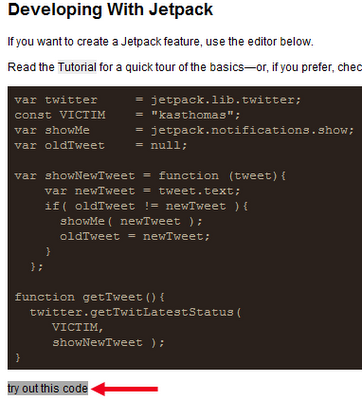
NOTE: Not visible in this screenshot are the final two lines of code:
var ONCE_A_MINUTE = 1000*60;
setInterval( getTweet, ONCE_A_MINUTE );
Note that right under the console, you'll find the words "try out this code." (See red arrow.) They are not highlighted by default and thus show no evidence of being clickable. But if you roll your mouse over the words, they get a grey highlight as shown here.
Note: If you make an edit to your code and click "try out this code" a second time, you may find that nothing happens until you refresh the entire page in the browser. Fortunately, you don't lose your work. But it feels scary nonetheless to refresh the page immediately after making a code echange.
I find it really odd that Jetpack has these obvious user-interface design gaffes. These aren't bugs but straight-out poor UI design decisions. What makes it so odd is that some world-class UI experts (such as Aza Raskin) are involved with Jetpack. Guys. Come on. I mean, really.
Maybe I'll do a code runthrough (for something a little more interesting than the above code) next time. For now, note that the code shown above makes use of Jetpack's built-in Twitter library (which wraps Twitter API functions and simplifies some of the AJAX calls, although I don't know why I should have to learn Jetpack's own Twitter API now). The code shown above simply checks Twitter every 60 seconds for any updates created by a particular user (me, in this case). If a new update is found, the relevant tweet is shown in a toaster notification in the bottom righthand corner of the desktop:
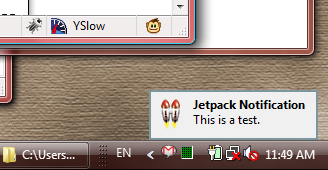
So far so good. But what if you want to give your script to a friend? How does your friend install it? Surely not by using the Bespin console?
Well, assuming your friend has installed the Jetpack add-on already, you can give him or her the script in a text file called something like myscript.jetpack.js. Or better yet, put that script online somewhere. Then you also need to have a page somewhere that contains this line in the HTML (in the head portion):
<link rel="jetpack" href="myscript.jetpack.js" name="TabList">
When your friend opens the page that contains this line, a warning-strip will appear at the top of the Firefox window saying that the page contains a script; do you want to install it? Answer yes, and you get a big scary red page that, if you scroll to the bottom, has these buttons:
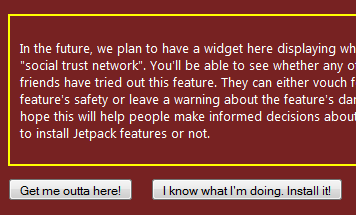
Obviously, you need to click the button on the right. At that point, the script will be installed and "live."
There's a lot more to Jetpack development than what I've described here, but this should be enough to get you started. Next time I'll present a (marginally) more meaningful code example so you can get yet another taste of what Jetpack has to offer. Then I'll get back to blogging about more important things, like the hazards of chewing gum while programming, or the high cost of not doing adequate usability testing.
Or maybe I'll just sit back, put my feet up, and tweet.
If you're already familiar with Greasemonkey, you'll grok the basics of Jetpack instantly. A fundamental pattern is firing a script when a page loads in Firefox (except, you have to start thinking in terms of "tabs," not pages). So for example,
jetpack.tabs.onReady( callback );This is a pretty common pattern. Your callback function is triggered when the target document's DOMContentLoaded event is fired. You can manipulate the DOM in your callback before the page actually renders in the browser window. So for example, you might want to filter nodes in some way, rearrange the page, make AJAX calls, attach your own event handlers to page objects, or wreak any manner of other havoc, before the page is actually displayed to the user. This is a standard Greasemonkey paradigm.
function callback( doc ) {
// do something
}
The "We're not in Kansas any more, Toto" feeling starts to hit you when you realize that your script can walk the entire list of open tabs and vulture any or all DOMs and/or window objects, for all frames in all tabs; something you can't do in Greasemonkey, since GM is scoped to the current window.
Also, you have access to jQuery. So if you want to see how many links a page contains, you can do:
var linkCount = $('a').length;and that's that. If you're not already a jQuery user, you'll want to vault that learning curve right away in order to get max value out of the Jetpack experience. It's not a requirement, but you're shortchanging yourself if you don't do it.Developing for Jetpack takes a little getting used to. First, of course, you have to install the Jetpack extension. The direct download link, at the moment, is here, but it could go stale by the time you read this. If so, go straight to https://jetpack.mozillalabs.com/.
To get to the development environment, you have to type "about:jetpack" in Firefox's address bar and hit Enter. When you do that, you'll see something like this:

There are several links across the top of the page (Welcome, Develop, etc.). It's not obvious that they are links, because they are not in the usual shade of blue and aren't underlined. Nevertheless, to do any actual code development in the embedded Bespin editor, you have to click the word "Develop" (which I've circled in red above). This brings up a page where, if you scroll down, you'll see a black-background text editor console.

NOTE: Not visible in this screenshot are the final two lines of code:
var ONCE_A_MINUTE = 1000*60;
setInterval( getTweet, ONCE_A_MINUTE );
Note that right under the console, you'll find the words "try out this code." (See red arrow.) They are not highlighted by default and thus show no evidence of being clickable. But if you roll your mouse over the words, they get a grey highlight as shown here.
Note: If you make an edit to your code and click "try out this code" a second time, you may find that nothing happens until you refresh the entire page in the browser. Fortunately, you don't lose your work. But it feels scary nonetheless to refresh the page immediately after making a code echange.
I find it really odd that Jetpack has these obvious user-interface design gaffes. These aren't bugs but straight-out poor UI design decisions. What makes it so odd is that some world-class UI experts (such as Aza Raskin) are involved with Jetpack. Guys. Come on. I mean, really.
Maybe I'll do a code runthrough (for something a little more interesting than the above code) next time. For now, note that the code shown above makes use of Jetpack's built-in Twitter library (which wraps Twitter API functions and simplifies some of the AJAX calls, although I don't know why I should have to learn Jetpack's own Twitter API now). The code shown above simply checks Twitter every 60 seconds for any updates created by a particular user (me, in this case). If a new update is found, the relevant tweet is shown in a toaster notification in the bottom righthand corner of the desktop:

So far so good. But what if you want to give your script to a friend? How does your friend install it? Surely not by using the Bespin console?
Well, assuming your friend has installed the Jetpack add-on already, you can give him or her the script in a text file called something like myscript.jetpack.js. Or better yet, put that script online somewhere. Then you also need to have a page somewhere that contains this line in the HTML (in the head portion):
<link rel="jetpack" href="myscript.jetpack.js" name="TabList">
When your friend opens the page that contains this line, a warning-strip will appear at the top of the Firefox window saying that the page contains a script; do you want to install it? Answer yes, and you get a big scary red page that, if you scroll to the bottom, has these buttons:

Obviously, you need to click the button on the right. At that point, the script will be installed and "live."
There's a lot more to Jetpack development than what I've described here, but this should be enough to get you started. Next time I'll present a (marginally) more meaningful code example so you can get yet another taste of what Jetpack has to offer. Then I'll get back to blogging about more important things, like the hazards of chewing gum while programming, or the high cost of not doing adequate usability testing.
Or maybe I'll just sit back, put my feet up, and tweet.
Subscribe to:
Posts (Atom)